

 |
市場調查報告書
商品編碼
2065508
中國資料中心GPU:市場佔有率分析、產業趨勢與統計及成長預測(2026-2031年)China Data Center GPU - Market Share Analysis, Industry Trends & Statistics, Growth Forecasts (2026 - 2031) |
||||||
※ 本網頁內容可能與最新版本有所差異。詳細情況請與我們聯繫。
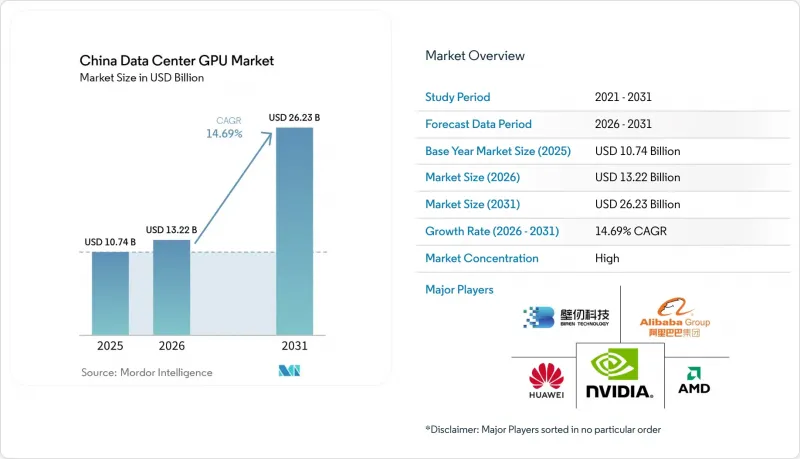
根據 Mordor Intelligence 預測,中國資料中心 GPU 市場規模預計到 2025 年將達到 107.4 億美元,到 2026 年將達到 132.2 億美元,到 2031 年將達到 262.3 億美元,2026 年至 2031 年的複合年成長率為 14.69%。
本報告按部署類型(雲端資料中心、企業/私人資料中心、邊緣資料中心)、GPU 類型(訓練 GPU、推理 GPU)、互連方式(基於 PCIe 的 GPU、高頻寬互連 GPU)、工作負載類型(人工智慧和機器學習、高效能運算等)以及最終用戶(超大規模資料中心業者伺服器/雲端服務供應商、企業、政府機構和研究機構)進行細分。市場預測以美元 (USD) 為單位。
中國資料中心GPU市場趨勢及洞察。
增加對人工智慧叢集超大規模資料中心業者的資本投資
位元組跳動已獲得1,600億元人民幣(約230億美元)的2026年資本支出資金,其中一半將用於購買GPU。同時,阿里巴巴正考慮在未來三年內將基礎設施投資增加至4,800億元。騰訊已將2026年的年度人工智慧預算加倍,達到約50億美元,但由於先前的供應短缺,其2025年的支出僅限於792億元人民幣。杭州37億美元的採購計畫是地方政府聯合投資協同促進企業支出的一個範例。美國出口許可證允許有限進口華為H200,但需繳納25%的關稅並限制進口數量達50%,促使超大規模資料中心超大規模資料中心業者尋求華為Ascend的替代方案。我們的營運中心位於長江Delta和粵港澳大灣區,在這些地區,多卡叢集的運行延遲可以低於 10 毫秒,每個機架的功率餘裕為 300 瓦。
由於出口限制,本地生產的GPU被取代。
從2025年中期開始,英偉達和AMD先進加速器的出口限制將更加嚴格,這將推動華為的顯示卡出貨量成長。華為計畫在2025年底「Ascend 910B」晶片出貨量超過5萬顆,到2026年「Ascend 950PR」晶片出貨量超過75萬顆。 910C和950PR的吞吐量達到H100的60-80%,並透過採用中芯國際的N+3工藝,降低了對台積電封裝能力的依賴。寒武紀2024年的銷售額預計成長67.4%,達到12.8億元。投資銀行預測,2027年,國內顯示卡自給率將達50%。優先發展國產技術的政策正在加速公共和軍事領域的國產化。甚至私人超大規模資料中心業者也在採用國產顯示卡,以規避授權風險。
先進封裝(CoWoS/HBM)產能瓶頸
台積電計畫在2026年初將其CoWoS晶圓產能提高四倍,達到每月約12萬片,但英偉達已獲得其中近60%的配額。 HBM3e顯存仍供不應求仍高達30%。國內廠商正採用7奈米製程製程及LPDDR顯存以避免排隊,但高階訓練晶片仍需CoWoS晶圓,導致交貨延遲超過50週。這套頸部迫使中國買家要么延長訓練計劃,要么支付高價購買稀缺的進口產品,從而限制了中國資料中心GPU市場的短期成長潛力。
細分市場分析
到 2025 年,邊緣設施將成為中國資料中心 GPU 市場成長最快的細分市場,預計到 2031 年將維持 20.3% 的複合年成長率。雲端資料中心,由於超大規模資料中心業者資料中心營運 10 萬個 GPU叢集以實現規模經濟,將繼續佔據主導地位,到 2025 年將佔中國資料中心 GPU 市場佔有率的 62.84%。
中國移動和中國聯通聯合開展了一項5G MEC先導計畫,該項目利用GPU進行雲端遊戲和即時影片串流傳輸,結果表明,當運算能力位於城市中心時,往返延遲可低於15毫秒。隨著租賃價格的下降,小規模專用機房的商業價值降低,許多中型企業正在將工作負載轉移到公共雲端,同時將敏感資料保留在本地邊緣節點上。中興通訊出貨的水冷式微型模組正在幫助解決零售和工廠環境中的空間和電力限制問題。
預計到2025年,推理加速器將佔中國資料中心GPU市場規模的59.21%,複合年成長率達16.8%,成為規模最大且成長最快的細分市場。雖然訓練GPU對於建立新的基礎模型至關重要,但由於主要集群已經存在,且推理功能正在推動短期收入成長,因此訓練GPU的擴張速度相對較慢。
阿里雲的TensorRT-LLM和vLLM服務在中中階LPDDR顯存GPU上每天可處理數十億次查詢,與基於HBM的方案相比,晶片成本可降低30-40%。華為出售給位元組跳動的950PR顯示卡,其重點在於1.56 PFLOPS的FP4推理吞吐量,而非FP16峰值效能。國內設計人員傾向選擇6奈米或7奈米製程,以避免CoWoS排隊,符合對價格敏感的推理部署需求。
其他好處:
- Excel格式的市場預測(ME)表
- 3個月的分析師支持
目錄
第1章:引言
- 研究假設和市場定義
- 調查範圍
第2章:調查方法
第3章執行摘要
第4章 市場狀況
- 市場概覽
- 市場促進因素
- 增加對人工智慧叢集超大規模資料中心業者的資本投資
- 政府代金券計畫旨在促進國內人工智慧運算發展
- 由於出口限制,國產GPU將被取代。
- GPU雲端租賃價格大幅下降
- 引進液冷技術,實現功率超過 80 kW 的機架。
- 「數據在東方,計算在西方」的政策使得利用低成本電力成為可能。
- 市場限制因素
- 先進封裝(CoWoS/HBM)產能瓶頸
- 軟體生態系和 CUDA 之間持續存在的差異
- 新成立的人工智慧中心運轉率率低
- 西部偏遠地區樞紐電網連接延誤。
- 產業價值鏈分析
- 監理情勢
- 技術展望
- 宏觀經濟因素對市場的影響
- 波特五力分析
第5章 市場規模與成長預測
- 依部署類型
- 雲端資料中心
- 企業/私人資料中心
- 邊緣資料中心
- 按GPU類型
- 訓練 GPU
- 用於推理的GPU
- 透過連接方式
- 基於 PCIe 的 GPU
- 高頻寬互連GPU
- 依工作負載類型
- 人工智慧(AI)和機器學習(ML)
- 高效能運算(HPC)(科學運算,不包括人工智慧)
- 資料分析(資料庫加速、查詢處理)
- 圖形和視覺化(VDI、渲染、數位雙胞胎)
- 最終用戶
- 超大規模資料中心業者雲端服務供應商/雲端服務供應商
- 公司
- 政府和研究機構
第6章 競爭情勢
- 市場集中度
- 策略趨勢
- 市佔率分析
- 公司簡介
- NVIDIA Corporation
- Advanced Micro Devices, Inc.
- Huawei Technologies Co., Ltd.
- Alibaba Group Holding Limited(Alibaba Cloud)
- Baidu, Inc.
- Tencent Holdings Ltd.
- Inspur Electronic Information Industry Co., Ltd.
- Lenovo Group Limited
- Intel Corporation
- Biren Technology Co., Ltd.
- Moore Threads Technology Co., Ltd.
- Cambricon Technologies Corp. Ltd.
- Hygon Information Technology Co., Ltd.
- Dawning Information Industry Co., Ltd.(Sugon)
- Enflame Technology Co., Ltd.
- MetaX Technology Inc.
- Iluvatar CoreX(Shanghai)Inc.
- JINGJIA Microelectronics Co., Ltd.
- China Telecom Corporation Limited
- ByteDance Ltd.(Volcengine)
- Shanghai Zhaoxin Semiconductor Co., Ltd.
第7章 市場機會與未來展望
According to Mordor Intelligence, the china data center GPU market size is projected to be USD 10.74 billion in 2025, USD 13.22 billion in 2026, and reach USD 26.23 billion by 2031, growing at a CAGR of 14.69% from 2026 to 2031.
This report is Segmented by Deployment Type (Cloud Data Centers, Enterprise/Private Data Centers, Edge Data Centers), GPU Type (Training GPUs, Inference GPUs), Interconnect (PCIe-Based GPUs, High-Bandwidth Interconnect GPUs), Workload Type (AI and ML, HPC, and More), and End-User (Hyperscalers/CSPs, Enterprises, Government and Research Institutions). Market Forecasts are Provided in Terms of Value (USD).
China Data Center GPU Market Trends and Insights
Rising Hyperscaler Capex for AI Clusters
ByteDance set aside CNY 160 billion (USD 23 billion) for 2026 capital expenditure and devoted half of that sum to GPU purchases, while Alibaba discussed raising infrastructure investment to RMB 480 billion over three years.Tencent doubled its annual AI budget to roughly USD 5 billion in 2026, although earlier supply tightness kept its 2025 spending to RMB 79.2 billion. Hangzhou's USD 3.7 billion procurement package illustrates municipal co-investment that compounds corporate outlays. United States export licenses allowed limited H200 imports with a 25% tariff and 50% volume cap, nudging hyperscalers toward Huawei Ascend alternatives. Activity centers on the Yangtze River Delta and the Greater Bay Area, where sub-10-millisecond latency and 300 watts per rack of power headroom accommodate multi-card clusters.
Export-Control-Driven Substitution Toward Local GPUs
The block on advanced NVIDIA and AMD accelerators since mid-2025 stimulated Huawei shipments that topped 50,000 Ascend 910B units by year-end 2025 and planned 750,000 Ascend 950PR chips for 2026. The 910C and 950PR deliver 60-80% of H100 throughput and ride SMIC's N+3 process, shrinking reliance on TSMC packaging capacity. Cambricon's 2024 revenue surged 67.4% to RMB 1.28 billion, and investment banks see domestic self-sufficiency reaching 50% by 2027. Mandates favoring indigenous tech speed adoption in public-sector and military workloads. Even private hyperscalers add domestic cards to hedge license risk.
Advanced Packaging (CoWoS/HBM) Capacity Bottlenecks
TSMC quadrupled CoWoS output to about 120,000 wafers per month by early 2026, yet NVIDIA locks down close to 60% of that allocation. HBM3e remains tight with a 30% global shortfall even after SK Hynix and Samsung expansions. Domestic vendors tap 7-nanometer nodes with LPDDR memory to avoid the queue, but high-end training chips still need CoWoS, delaying deliveries by more than 50 weeks. The bottleneck forces Chinese buyers to stretch training schedules or pay premiums for scarce imports, clipping near-term upside for the China data center GPU market.
Other drivers and restraints analyzed in the detailed report include:
- Government Vouchers Incentivizing Domestic AI Compute
- Liquid-Cooling Adoption Enabling 80 kW+ Racks
- Rapid Price Declines in GPU Cloud Leasing
- Persistent Software Ecosystem Gap vs CUDA
For complete list of drivers and restraints, kindly check the Table Of Contents.
Segment Analysis
Edge facilities represented the fastest-growing slice of the China data center GPU market during 2025 and are forecast to post a 20.3% CAGR through 2031. Cloud data centers still dominate with 62.84% of China's data center GPU market share in 2025, thanks to hyperscalers that run 100,000-GPU clusters to achieve economies of scale.
China Mobile and China Unicom staged 5G MEC pilots that use GPUs for cloud gaming and real-time video, proving that sub-15-millisecond round-trip is achievable when compute sits within the city core. Lower leasing prices weaken the business case for small private halls, so many mid-sized firms burst workloads into public cloud but keep sensitive data on on-premise edge nodes. Liquid-cooled micro-modules shipping from ZTE help solve space and power limitations in retail and factory environments.
Inference accelerators held 59.21% of the China data center GPU market size in 2025 and are projected to grow at a 16.8% CAGR, making them both the largest and fastest segment. Training GPUs, while indispensable for new foundation models, expand more slowly as major clusters already exist and inference drives near-term revenue.
Alibaba Cloud's TensorRT-LLM and vLLM services can answer billions of daily calls on mid-tier GPUs paired with LPDDR memory, cutting chip costs by 30-40% against HBM-based alternatives. Huawei's 950PR sold to ByteDance focuses on inference throughput with 1.56 PFLOPS FP4 rather than peak FP16 performance. Domestic designers choose 6- or 7-nanometer nodes to dodge CoWoS queues, aligning with price-sensitive inference deployments.
List of Companies Covered in this Report:
- NVIDIA Corporation
- Advanced Micro Devices, Inc.
- Huawei Technologies Co., Ltd.
- Alibaba Group Holding Limited (Alibaba Cloud)
- Baidu, Inc.
- Tencent Holdings Ltd.
- Inspur Electronic Information Industry Co., Ltd.
- Lenovo Group Limited
- Intel Corporation
- Biren Technology Co., Ltd.
- Moore Threads Technology Co., Ltd.
- Cambricon Technologies Corp. Ltd.
- Hygon Information Technology Co., Ltd.
- Dawning Information Industry Co., Ltd. (Sugon)
- Enflame Technology Co., Ltd.
- MetaX Technology Inc.
- Iluvatar CoreX (Shanghai) Inc.
- JINGJIA Microelectronics Co., Ltd.
- China Telecom Corporation Limited
- ByteDance Ltd. (Volcengine)
- Shanghai Zhaoxin Semiconductor Co., Ltd.
Additional Benefits:
- The market estimate (ME) sheet in Excel format
- 3 months of analyst support
TABLE OF CONTENTS
1 INTRODUCTION
- 1.1 Study Assumptions and Market Definition
- 1.2 Scope of the Study
2 RESEARCH METHODOLOGY
3 EXECUTIVE SUMMARY
4 MARKET LANDSCAPE
- 4.1 Market Overview
- 4.2 Market Drivers
- 4.2.1 Rising Hyperscaler Capex for AI Clusters
- 4.2.2 Government Vouchers Incentivizing Domestic AI Compute
- 4.2.3 Export-Control-Driven Substitution Toward Local GPUs
- 4.2.4 Rapid Price Declines in GPU Cloud Leasing
- 4.2.5 Liquid-Cooling Adoption Enabling 80 kW+ Racks
- 4.2.6 East-Data West-Compute Policy Unlocking Low-Cost Power
- 4.3 Market Restraints
- 4.3.1 Advanced Packaging (CoWoS/HBM) Capacity Bottlenecks
- 4.3.2 Persistent Software Ecosystem Gap vs CUDA
- 4.3.3 Low Utilization Rates in Newly Built AI Centers
- 4.3.4 Grid-Connection Delays in Remote Western Hubs
- 4.4 Industry Value Chain Analysis
- 4.5 Regulatory Landscape
- 4.6 Technological Outlook
- 4.7 Impact of Macroeconomic Factors on the Market
- 4.8 Porter's Five Forces Analysis
- 4.8.1 Threat of New Entrants
- 4.8.2 Bargaining Power of Suppliers
- 4.8.3 Bargaining Power of Buyers
- 4.8.4 Threat of Substitutes
- 4.8.5 Competitive Rivalry
5 MARKET SIZE AND GROWTH FORECASTS (VALUE)
- 5.1 By Deployment Type
- 5.1.1 Cloud Data Centers
- 5.1.2 Enterprise / Private Data Centers
- 5.1.3 Edge Data Centers
- 5.2 By GPU Type
- 5.2.1 Training GPUs
- 5.2.2 Inference GPUs
- 5.3 By Interconnect
- 5.3.1 PCIe-Based GPUs
- 5.3.2 High-Bandwidth Interconnect GPUs
- 5.4 By Workload Type
- 5.4.1 Artificial Intelligence (AI) and Machine Learning (ML)
- 5.4.2 High-Performance Computing (HPC) (non-AI scientific computing)
- 5.4.3 Data Analytics (database acceleration, query processing)
- 5.4.4 Graphics and Visualization (VDI, rendering, digital twins)
- 5.5 By End-User
- 5.5.1 Hyperscalers / Cloud Service Providers
- 5.5.2 Enterprises
- 5.5.3 Government and Research Institutions
6 COMPETITIVE LANDSCAPE
- 6.1 Market Concentration
- 6.2 Strategic Moves
- 6.3 Market Share Analysis
- 6.4 Company Profiles (includes Global Level Overview, Market Level Overview, Core Segments, Financials as available, Strategic Information, Market Rank/Share, Products and Services, Recent Developments)
- 6.4.1 NVIDIA Corporation
- 6.4.2 Advanced Micro Devices, Inc.
- 6.4.3 Huawei Technologies Co., Ltd.
- 6.4.4 Alibaba Group Holding Limited (Alibaba Cloud)
- 6.4.5 Baidu, Inc.
- 6.4.6 Tencent Holdings Ltd.
- 6.4.7 Inspur Electronic Information Industry Co., Ltd.
- 6.4.8 Lenovo Group Limited
- 6.4.9 Intel Corporation
- 6.4.10 Biren Technology Co., Ltd.
- 6.4.11 Moore Threads Technology Co., Ltd.
- 6.4.12 Cambricon Technologies Corp. Ltd.
- 6.4.13 Hygon Information Technology Co., Ltd.
- 6.4.14 Dawning Information Industry Co., Ltd. (Sugon)
- 6.4.15 Enflame Technology Co., Ltd.
- 6.4.16 MetaX Technology Inc.
- 6.4.17 Iluvatar CoreX (Shanghai) Inc.
- 6.4.18 JINGJIA Microelectronics Co., Ltd.
- 6.4.19 China Telecom Corporation Limited
- 6.4.20 ByteDance Ltd. (Volcengine)
- 6.4.21 Shanghai Zhaoxin Semiconductor Co., Ltd.
7 MARKET OPPORTUNITIES AND FUTURE OUTLOOK
- 7.1 White-Space and Unmet-Need Assessment
 亞太地區資料中心GPU:市場佔有率分析、產業趨勢與統計及成長預測(2026-2031年)北美資料中心GPU:市佔率分析、產業趨勢與統計及成長預測(2026-2031年)德國資料中心GPU:市場佔有率分析、產業趨勢與統計及成長預測(2026-2031年)日本資料中心GPU市場:市佔率分析、產業趨勢與統計及成長預測(2026-2031年)歐洲資料中心GPU:市佔率分析、產業趨勢與統計及成長預測(2026-2031年)美國資料中心GPU:市場佔有率分析、產業趨勢與統計及成長預測(2026-2031年)英國資料中心GPU:市佔率分析、產業趨勢與統計及成長預測(2026-2031年)
亞太地區資料中心GPU:市場佔有率分析、產業趨勢與統計及成長預測(2026-2031年)北美資料中心GPU:市佔率分析、產業趨勢與統計及成長預測(2026-2031年)德國資料中心GPU:市場佔有率分析、產業趨勢與統計及成長預測(2026-2031年)日本資料中心GPU市場:市佔率分析、產業趨勢與統計及成長預測(2026-2031年)歐洲資料中心GPU:市佔率分析、產業趨勢與統計及成長預測(2026-2031年)美國資料中心GPU:市場佔有率分析、產業趨勢與統計及成長預測(2026-2031年)英國資料中心GPU:市佔率分析、產業趨勢與統計及成長預測(2026-2031年) 資料中心圖形處理器 (GPU) 市場預測至 2034 年:按部署模式、功能、最終用戶和地區分類的全球分析AI資料中心GPU:市佔率分析、產業趨勢與統計及成長預測(2026-2031年)
資料中心圖形處理器 (GPU) 市場預測至 2034 年:按部署模式、功能、最終用戶和地區分類的全球分析AI資料中心GPU:市佔率分析、產業趨勢與統計及成長預測(2026-2031年) 資料中心GPU市場:2026年至2032年全球市場預測,依產品、記憶體容量、伺服器密度、功耗範圍、應用、部署模式及最終用戶分類
資料中心GPU市場:2026年至2032年全球市場預測,依產品、記憶體容量、伺服器密度、功耗範圍、應用、部署模式及最終用戶分類