

 |
市場調查報告書
商品編碼
2065487
亞太地區資料中心GPU:市場佔有率分析、產業趨勢與統計及成長預測(2026-2031年)Asia-Pacific Data Center GPU - Market Share Analysis, Industry Trends & Statistics, Growth Forecasts (2026 - 2031) |
||||||
※ 本網頁內容可能與最新版本有所差異。詳細情況請與我們聯繫。
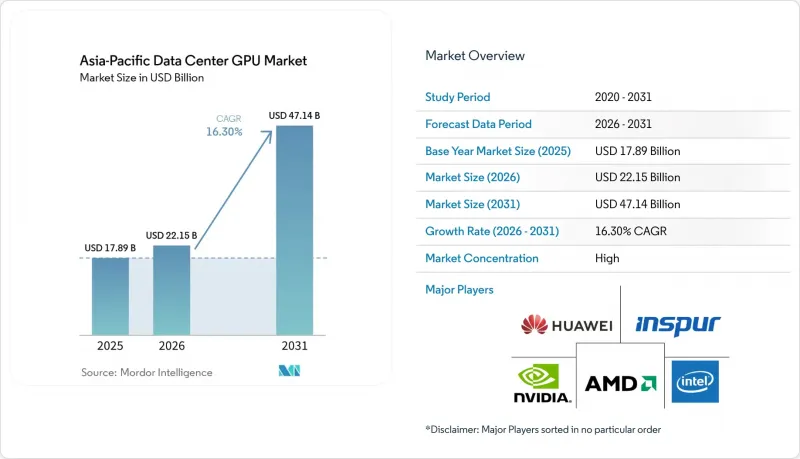
根據 Mordor Intelligence 預測,亞太地區資料中心 GPU 市場規模將從 2025 年的 178.9 億美元和 2026 年的 221.5 億美元成長到 2031 年的 471.4 億美元,2026 年至 2031 年的複合年成長率為 16.3%。
本報告按部署類型(例如,雲端資料中心)、GPU 類型(訓練 GPU 和推理 GPU)、互連方式(基於 PCIe 的 GPU 和高頻寬互連 GPU)、工作負載類型(人工智慧和機器學習、高效能運算及其他)、最終用戶(超大規模資料中心業者/雲端服務供應商、企業及其他)以及國家/地區(中國、日本、韓國、印度及其他)進行細分。市場預測以美元計價。
亞太地區資料中心GPU市場趨勢及洞察。
超大規模雲端資料中心人工智慧訓練工作負載激增
為了處理兆參數規模的模型訓練,超大規模雲端服務供應商正在部署超過10萬個加速器的叢集。微軟和OpenAI斥資1000億美元打造的突破性「星門」(Stargate)計畫雖然總部位於美國,但已為其他旨在實現類似規模的區域性企業樹立了標竿。騰訊雲計畫在2025年擴展其基礎設施,以滿足國內LLM(層級模型)開發者的激增需求;百度旗下的「文心」平台也持續增加H100加速卡,以確保每天2億用戶的回應時間低於1秒。隨著雲端服務供應商將亞太地區定位為全球最大的AI運算中心,該地區的資本支出預計將在2026年佔據全球整體超大規模資料中心業者服務供應商5,270億美元預算的相當大一部分。透過雲端交付的GPU即服務(GPUaaS)產品縮短了產品推出週期,但也使定價權集中在少數供應商手中,給無法獲得大型合約的小型競爭對手帶來了壓力。
「自主AI雲」的興起增加了對區域GPU叢集的需求。
目前,世界各國政府都要求高度敏感的人工智慧工作負載必須在本國基礎設施上運作。日本數位廳與富士通和微軟合作,於2024年投資1.6兆日圓(約103億美元)建置主權雲端區。同年,印度的「半導體使命2.0」計畫也撥款108億美元,目標是到2030年將其對進口GPU的依賴度降低40%。 2025年,中國發布指令,要求政府人工智慧推理處理在2027年前遷移到昇騰GPU,並保證每年數千塊國產GPU的出貨量。這種平行架構會使基礎設施支出翻倍,並降低規模經濟效益,因為服務提供者必須為主權用戶和商業用戶分別維護獨立的資源池。
出口限制導致無法取得最新GPU
華盛頓於2023年10月宣布的法規禁止向中國出售H200級GPU,將其性能限制在與H100相當的水平。 2025年加徵的25%關稅進一步推高了採購價格。作為應對措施,位元組跳動和阿里巴巴訂購了60萬顆華為Ascend 910C,但由於每顆晶片的吞吐量僅為H100 變壓器的60-70%,因此這屬於超額採購。此外,6-12個月的許可核准延遲也加劇了大學和研究機構的不確定性。
細分市場分析
到2025年,雲端設施將佔據亞太地區資料中心GPU市場佔有率的63.45%。這反映了超大規模資料中心超大規模資料中心業者的採購能力以及多租戶模式的經濟優勢。同時,受5G網路密度不斷提高的推動,邊緣站點預計到2031年將以17.88%的複合年成長率成長,因為5G需要小於10毫秒的響應時間。此外,隨著銀行和製藥公司將推理處理內部化以滿足資料居住要求,亞太地區資料中心GPU市場規模也在擴大,這與企業私有資料中心的發展密切相關。
集中式雲端叢集的利用率已超過 85%,具有價格優勢;而邊緣部署則因 AR 導航和智慧工廠控制等對延遲敏感的新型服務而獲得更高的收入。企業可以在保持完全策略控制的同時,縮小本地叢集的規模,這使其成為高度敏感工作負載和隱私法律更為嚴格的地區的理想選擇。
預計到2025年,推理加速器將佔據亞太資料中心GPU市場佔有率的58.77%,並將在2031年之前以17.24%的複合年成長率成長,因為工作負載正從模型研究轉向生產環境。雖然用於訓練的GPU對於最先進的模型仍然至關重要,但隨著單一訓練好的模型可以處理數百萬次推理調用,其市場佔有率正在下降。
與H100訓練晶片相比,NVIDIA的L4和L40S、AMD的MI300X以及華為的Ascend 310功耗更低、價格更便宜。得益於INT8和INT4量化技術,亞太地區資料中心推理GPU市場持續成長,使得舊款GPU在維持競爭力的同時,也能降低每個代幣的功耗。
其他好處:
- Excel格式的市場預測(ME)表
- 3個月的分析師支持
目錄
第1章:引言
- 研究假設和市場定義
- 調查範圍
第2章:調查方法
第3章執行摘要
第4章 市場狀況
- 市場概覽
- 市場促進因素
- 超大規模雲端資料中心人工智慧訓練工作負載激增
- 擴展邊緣資料中心以支援 5G 和物聯網流量
- 亞太地區政府對國內人工智慧半導體製造的獎勵措施
- 採用液冷技術可以提高GPU機架的密度。
- 自主人工智慧雲端的興起增加了對本地GPU叢集的需求。
- 企業永續發展目標旨在促進GPU整合以提高能源效率
- 市場限制因素
- 先進GPU封裝領域持續存在的供應鏈限制
- 對基於GPU的基礎設施進行大量資本投資
- 出口限制導致無法取得最新GPU
- 企業IT團隊在最佳化GPU工作負載方面存在技能差距
- 產業價值鏈分析
- 監理情勢
- 技術展望
- 宏觀經濟因素對市場的影響
- 波特五力分析
第5章 市場規模與成長預測
- 依部署類型
- 雲端資料中心
- 企業/私人資料中心
- 邊緣資料中心
- 按GPU類型
- 訓練 GPU
- 用於推理的GPU
- 透過連接方式
- 基於 PCIe 的 GPU
- 高頻寬互連GPU
- 依工作負載類型
- 人工智慧(AI)和機器學習(ML)
- 高效能運算(HPC)(科學運算,不包括人工智慧)
- 資料分析(資料庫加速、查詢處理)
- 圖形和視覺化(VDI、渲染、數位雙胞胎)
- 最終用戶
- 超大規模資料中心業者雲端服務供應商/雲端服務供應商
- 公司
- 政府和研究機構
- 國家
- 中國
- 日本
- 韓國
- 印度
- 東南亞
- 其他亞太國家
第6章 競爭情勢
- 市場集中度
- 策略趨勢
- 市佔率分析
- 公司簡介
- Nvidia Corporation
- Advanced Micro Devices Inc.
- Intel Corporation
- Huawei Technologies Co. Ltd.
- Tencent Cloud
- Baidu Inc.
- Amazon Web Services Inc.
- Microsoft Corporation
- Google LLC
- Samsung Electronics Co. Ltd.
- Inspur Group
- Giga Computing Technology Co. Ltd.
- Super Micro Computer Inc.
- Lenovo Group Limited
- NEC Corporation
- H3C Technologies Co. Ltd.
- Fujitsu Limited
第7章 市場機會與未來展望
According to Mordor Intelligence, the asia-Pacific data center GPU market size is projected to expand from USD 17.89 billion in 2025 and USD 22.15 billion in 2026 to USD 47.14 billion by 2031, registering a 16.3% CAGR between 2026 and 2031.
This report is Segmented by Deployment Type (Cloud Data Centers, and More), GPU Type (Training GPUs and Inference GPUs), Interconnect (PCIe-Based GPUs and High-Bandwidth Interconnect GPUs), Workload Type (AI and ML, HPC, and More), End-User (Hyperscalers/CSPs, Enterprises, and More), and by Country (China, Japan, South Korea, India, and More). The Market Forecasts are Provided in Value (USD).
Asia-Pacific Data Center GPU Market Trends and Insights
Surge in AI Training Workloads in Hyperscale Cloud Data Centers
Hyperscale providers are rolling out clusters with more than 100,000 accelerators to support trillion-parameter model training. Microsoft and OpenAI's landmark USD 100 billion Stargate project, though U.S.-based, set the bar for regional players racing to reach comparable scale. Tencent Cloud expanded its fleet in 2025 to meet skyrocketing demand from domestic LLM developers, and Baidu's Wenxin platform added continuous batches of H100 cards to keep sub-second response for 200 million daily users. Regional capital-expenditure outlays are on pace to claim a significant share of the global USD 527 billion hyperscaler budget in 2026 as cloud operators position Asia-Pacific as the world's largest AI compute hub. Cloud-delivered GPU-as-a-Service products shorten launch cycles but concentrate pricing power in a handful of vendors, pressuring smaller rivals unable to secure volume contracts.
Rise of Sovereign AI Clouds Demanding In-Region GPU Clusters
Governments now require sensitive AI workloads to run on domestic infrastructure. Japan's Digital Agency, working with Fujitsu and Microsoft, committed JPY 1.6 trillion (USD 10.3 billion) in 2024 to build sovereign cloud zones. India's Semiconductor Mission 2.0 allocated USD 10.8 billion the same year, aiming to reduce reliance on imported GPUs by 40% before 2030. China issued directives in 2025 mandating that government AI inference migrate to Ascend GPUs by 2027, guaranteeing thousands of annual domestic shipments. Such parallel architectures double infrastructure outlays because providers must maintain dedicated pools for sovereign and commercial tenants, diluting economies of scale.
Export Control Regulations Limiting Access to Latest GPUs
Washington's October 2023 rules block H200-class GPU sales to China, capping performance ceilings at H100 equivalents. Tariffs of 25% imposed in 2025 further inflate acquisition prices. ByteDance and Alibaba responded by booking 600,000 Huawei Ascend 910C units for 2025, yet each chip delivers only 60-70% of the H100 transformer's throughput, prompting over-provisioning. License processing delays of six to twelve months amplify planning uncertainty for universities and research labs.
Other drivers and restraints analyzed in the detailed report include:
- Government Incentives for Domestic AI Semiconductor Manufacturing in the Asia-Pacific
- Expansion of Edge Data Centers for 5G and IoT Traffic
- High Capital Expenditure for GPU-Based Infrastructure
For complete list of drivers and restraints, kindly check the Table Of Contents.
Segment Analysis
Cloud venues accounted for 63.45% of the Asia-Pacific data center GPU market share in 2025, reflecting hyperscalers' unmatched buying power and multitenancy economics. Edge sites, however, post a 17.88% CAGR through 2031, spurred by 5G densification that requires sub-10-millisecond response loops. The Asia-Pacific data center GPU market size tied to private enterprise data centers also expands, as banks and pharmaceutical firms internalize inference to meet data residency.
Centralized cloud clusters reach utilization above 85%, enabling price leadership, while edge rollouts monetize new latency-sensitive services such as AR wayfinding and smart-factory controls. Enterprises can keep on-prem clusters smaller while maintaining full policy control, an attractive option for confidential workloads and regions subject to stricter privacy laws.
Inference accelerators captured 58.77% of the Asia-Pacific data center GPU market share in 2025 and will grow at a 17.24% CAGR through 2031 as workloads migrate from model research to production. Training GPUs remain indispensable for frontier models, yet their share declines as every trained model fuels millions of inference calls.
NVIDIA's L4 and L40S, AMD's MI300X, and Huawei's Ascend 310 offer lower power draw and price points than H100 training silicon. The Asia-Pacific data center GPU market for inference continues to grow, thanks to INT8 and INT4 quantization, enabling older boards to remain competitive while driving down watts per token.
List of Companies Covered in this Report:
- Nvidia Corporation
- Advanced Micro Devices Inc.
- Intel Corporation
- Huawei Technologies Co. Ltd.
- Tencent Cloud
- Baidu Inc.
- Amazon Web Services Inc.
- Microsoft Corporation
- Google LLC
- Samsung Electronics Co. Ltd.
- Inspur Group
- Giga Computing Technology Co. Ltd.
- Super Micro Computer Inc.
- Lenovo Group Limited
- NEC Corporation
- H3C Technologies Co. Ltd.
- Fujitsu Limited
Additional Benefits:
- The market estimate (ME) sheet in Excel format
- 3 months of analyst support
TABLE OF CONTENTS
1 INTRODUCTION
- 1.1 Study Assumptions and Market Definition
- 1.2 Scope of the Study
2 RESEARCH METHODOLOGY
3 EXECUTIVE SUMMARY
4 MARKET LANDSCAPE
- 4.1 Market Overview
- 4.2 Market Drivers
- 4.2.1 Surge in AI Training Workloads in Hyperscale Cloud Data Centers
- 4.2.2 Expansion of Edge Data Centers for 5G and IoT Traffic
- 4.2.3 Government Incentives for Domestic AI Semiconductor Manufacturing in Asia-Pacific
- 4.2.4 Adoption of Liquid Cooling Enabling Higher GPU Rack Density
- 4.2.5 Rise of Sovereign AI Clouds Demanding In-Region GPU Clusters
- 4.2.6 Corporate Sustainability Targets Driving GPU Consolidation for Energy Efficiency
- 4.3 Market Restraints
- 4.3.1 Ongoing Supply Chain Constraints for Advanced GPU Packaging
- 4.3.2 High Capital Expenditure for GPU-Based Infrastructure
- 4.3.3 Export Control Regulations Limiting Access to Latest GPUs
- 4.3.4 Skill Gap in Optimizing GPU Workloads Among Enterprise IT Teams
- 4.4 Industry Value Chain Analysis
- 4.5 Regulatory Landscape
- 4.6 Technological Outlook
- 4.7 Impact of Macroeconomic Factors on the Market
- 4.8 Porter's Five Forces Analysis
- 4.8.1 Threat of New Entrants
- 4.8.2 Bargaining Power of Suppliers
- 4.8.3 Bargaining Power of Buyers
- 4.8.4 Threat of Substitutes
- 4.8.5 Industry Rivalry
5 MARKET SIZE AND GROWTH FORECASTS (VALUE)
- 5.1 By Deployment Type
- 5.1.1 Cloud Data Centers
- 5.1.2 Enterprise / Private Data Centers
- 5.1.3 Edge Data Centers
- 5.2 By GPU Type
- 5.2.1 Training GPUs
- 5.2.2 Inference GPUs
- 5.3 By Interconnect
- 5.3.1 PCIe-Based GPUs
- 5.3.2 High-Bandwidth Interconnect GPUs
- 5.4 By Workload Type
- 5.4.1 Artificial Intelligence (AI) and Machine Learning (ML)
- 5.4.2 High-Performance Computing (HPC) (non-AI scientific computing)
- 5.4.3 Data Analytics (database acceleration, query processing)
- 5.4.4 Graphics and Visualization (VDI, rendering, digital twins)
- 5.5 By End-User
- 5.5.1 Hyperscalers / Cloud Service Providers
- 5.5.2 Enterprises
- 5.5.3 Government and Research Institutions
- 5.6 By Country
- 5.6.1 China
- 5.6.2 Japan
- 5.6.3 South Korea
- 5.6.4 India
- 5.6.5 Southeast Asia
- 5.6.6 Rest of Asia-Pacific
6 COMPETITIVE LANDSCAPE
- 6.1 Market Concentration
- 6.2 Strategic Moves
- 6.3 Market Share Analysis
- 6.4 Company Profiles (includes Global Level Overview, Market Level Overview, Core Segments, Financials as available, Strategic Information, Market Rank/Share, Products and Services, Recent Developments)
- 6.4.1 Nvidia Corporation
- 6.4.2 Advanced Micro Devices Inc.
- 6.4.3 Intel Corporation
- 6.4.4 Huawei Technologies Co. Ltd.
- 6.4.5 Tencent Cloud
- 6.4.6 Baidu Inc.
- 6.4.7 Amazon Web Services Inc.
- 6.4.8 Microsoft Corporation
- 6.4.9 Google LLC
- 6.4.10 Samsung Electronics Co. Ltd.
- 6.4.11 Inspur Group
- 6.4.12 Giga Computing Technology Co. Ltd.
- 6.4.13 Super Micro Computer Inc.
- 6.4.14 Lenovo Group Limited
- 6.4.15 NEC Corporation
- 6.4.16 H3C Technologies Co. Ltd.
- 6.4.17 Fujitsu Limited
7 MARKET OPPORTUNITIES AND FUTURE OUTLOOK
- 7.1 White-Space and Unmet-Need Assessment
 中國資料中心GPU:市場佔有率分析、產業趨勢與統計及成長預測(2026-2031年)北美資料中心GPU:市佔率分析、產業趨勢與統計及成長預測(2026-2031年)德國資料中心GPU:市場佔有率分析、產業趨勢與統計及成長預測(2026-2031年)日本資料中心GPU市場:市佔率分析、產業趨勢與統計及成長預測(2026-2031年)歐洲資料中心GPU:市佔率分析、產業趨勢與統計及成長預測(2026-2031年)美國資料中心GPU:市場佔有率分析、產業趨勢與統計及成長預測(2026-2031年)英國資料中心GPU:市佔率分析、產業趨勢與統計及成長預測(2026-2031年)
中國資料中心GPU:市場佔有率分析、產業趨勢與統計及成長預測(2026-2031年)北美資料中心GPU:市佔率分析、產業趨勢與統計及成長預測(2026-2031年)德國資料中心GPU:市場佔有率分析、產業趨勢與統計及成長預測(2026-2031年)日本資料中心GPU市場:市佔率分析、產業趨勢與統計及成長預測(2026-2031年)歐洲資料中心GPU:市佔率分析、產業趨勢與統計及成長預測(2026-2031年)美國資料中心GPU:市場佔有率分析、產業趨勢與統計及成長預測(2026-2031年)英國資料中心GPU:市佔率分析、產業趨勢與統計及成長預測(2026-2031年) 資料中心圖形處理器 (GPU) 市場預測至 2034 年:按部署模式、功能、最終用戶和地區分類的全球分析AI資料中心GPU:市佔率分析、產業趨勢與統計及成長預測(2026-2031年)
資料中心圖形處理器 (GPU) 市場預測至 2034 年:按部署模式、功能、最終用戶和地區分類的全球分析AI資料中心GPU:市佔率分析、產業趨勢與統計及成長預測(2026-2031年) 資料中心GPU市場:2026年至2032年全球市場預測,依產品、記憶體容量、伺服器密度、功耗範圍、應用、部署模式及最終用戶分類
資料中心GPU市場:2026年至2032年全球市場預測,依產品、記憶體容量、伺服器密度、功耗範圍、應用、部署模式及最終用戶分類