

 |
市場調查報告書
商品編碼
2065496
超大規模資料中心GPU:市場佔有率分析、產業趨勢與統計及成長預測(2026-2031年)Hyperscale Data Center Graphics Processing Unit (GPU) - Market Share Analysis, Industry Trends & Statistics, Growth Forecasts (2026 - 2031) |
||||||
※ 本網頁內容可能與最新版本有所差異。詳細情況請與我們聯繫。
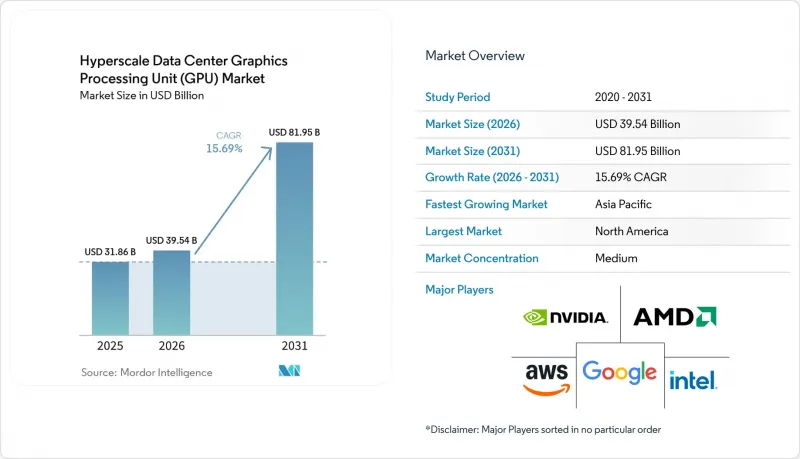
預計超大規模資料中心 GPU 的市場規模將從 2025 年的 318.6 億美元和 2026 年的 395.4 億美元成長到 2031 年的 819.5 億美元,2026 年至 2031 年的複合年成長率為 15.69%。
本報告按部署類型(雲端資料中心、企業/私人資料中心、邊緣資料中心)、GPU 類型(訓練 GPU、推理 GPU)、互連方式(基於 PCIe 的 GPU、高頻寬互連 GPU)、工作負載類型(人工智慧和機器學習、高效能運算、資料分析等)以及地區進行細分。市場預測以美元 (USD) 為單位。
超大規模資料中心圖形處理器 (GPU) 市場的全球趨勢與洞察。
雲端資料中心採用人工智慧和機器學習工作負載
雲端平台已將GPU從專用加速器轉變為標準基礎架構。微軟Azure上AI最佳化虛擬機器和AWS上Trainium2實例的出現,降低了企業客戶遷移傳統機器學習流程的門檻。資本配置反映的是長期投資而非實驗性嘗試,Meta累計2026年AI計算領域的投資將達到650億美元,其中大部分將分配給多模態學習叢集。與傳統伺服器相比,GPU的功率密度提高了10到20倍,這促使資料中心需要重新設計,採用整合機架級液冷和改進的配電方式。工作負載的多樣性如今涵蓋了視覺、建議和自動駕駛等領域,每項應用都需要推理最佳化的GPU和訓練單元的組合,這從根本上推動了超大規模資料中心GPU市場的成長。
生成式人工智慧模型訓練叢集的快速擴張
隨著參數數量從數十億成長到數兆,運營商被迫構建千兆次級(petaflop)叢集。 xAI位於孟菲斯的資料中心預計到2027年將擴展至100萬個GPU,而Mistral AI位於巴黎的資料中心也在歐洲部署了類似的模式。集中化可以最大限度地提高設備利用率,並允許資本支出(CAPEX)在後續的模型迭代中攤銷,但只有超大規模資料中心業者才能承擔數十億美元的建造成本。從技術角度來看,水冷和NVLink 5.0等技術可以將GPU之間的延遲降低到1微秒以下,並且70多個GPU托架可以被視為一個邏輯設備。因此,超大規模資料中心GPU市場形成了一種協同效應,叢集容量隨著模型規模的每次成長而呈指數級顯著成長。
對超大規模GPU叢集的高額資本投入
Blackwell GB200 NVL72 每機架的價格估計在 300 萬至 400 萬美元之間,不包括設施成本。 Oracle Oracle億美元的部署規模清楚地表明了進入該市場的最低成本,一個 10 兆瓦叢集的年電力成本可能高達 1000 萬美元。由於平均運轉率維持在 60% 至 70%,供應商被迫超額保障容量,導致投資回收期延長,並給中型雲端服務供應商的營運帶來壓力。因此,只有那些能夠獲得低成本可再生能源的大型供應商才能在培訓領域保持領先地位,從而減緩了超大規模資料中心 GPU 市場的短期成長。
細分市場分析
邊緣運算設施預計將以 19.3% 的複合年成長率成長,而集中式超大規模資料中心預計將以 15% 左右的複合年成長率成長,這反映出即時推理在汽車、智慧城市感測器和工業機器人等領域的作用日益增強。與雲端站點相關的超大規模資料中心的 GPU 市場規模仍佔據主導地位,但隨著 AWS Outposts 等供應商提供本地雲端管理服務,其市場佔有率略有下降。事實上,雙架構平衡正在形成:100MW 的巨型資料中心使用 1 兆個參數訓練模型,而 1MW 的微型資料中心則能在用戶回應後 10 毫秒內做出決策。
資本配置的重點在於這一頻譜的兩端。亞馬遜計畫在2030年投資2,000億美元建造巨型資料中心,而英偉達IGX Orin的出貨量則顯示OEM廠商對邊緣運算設備的需求強勁。金融服務和醫療保健相關企業為了滿足資料主權法規的要求,維護著小規模的私有叢集,而這一細分市場仍然是更廣泛的超大規模資料中心GPU市場的基礎。隨著利用率分析的改進,預計部分推理負荷將根據區域需求曲線在邊緣和核心之間轉移。
到2025年,訓練板將佔銷售額的56.7%,成為供應商現金流的主要驅動力。然而,由於精度和功耗要求較低的推理專用設備的激增,超大規模資料中心業者正經歷快速成長。推理GPU預計將以每年18.5%的速度成長,這反映了模型規模翻倍的速度,而這將需要數千張卡片進行分散式處理。
儘管超大規模資料中心推理硬體的GPU市場規模仍然較小,但隨著對話式人工智慧、搜尋增強生成(RAG)和即時輔助駕駛等技術成為主流軟體,到2031年,其市場價值可能超過總價值的40%。 NVIDIA的L4、AWS的Inferentia2和Google的TPU v5e都清楚地展現了其經濟可行性;雖然它們的每瓦浮點運算次數(FLOPs)較低,但每次請求的成本更低。因此,層級構造產品架構應運而生:在訓練叢集中優先考慮尖端內存頻寬,而較舊的晶片則作為推理的主力軍,煥發新生,獲得豐厚的盈利。
區域分析
預計到2025年,北美仍將維持42.8%的銷售佔有率,並持續發揮其無可匹敵的購買力,這得益於亞馬遜、微軟、谷歌和Meta等公司在人工智慧基礎設施領域投入的數千億美元。對中國出口頂級GPU的限制,無意中將更多有限的供應轉向了美國國內市場,進一步鞏固了該地區在超大規模資料中心GPU市場的主導地位。多倫多和蒙特婁的加拿大叢集受益於低成本的水力發電和受過高等教育的人才,而墨西哥蓬勃發展的近岸外包經濟則推動了專注於物流機器人的邊緣節點的發展。
亞太地區是成長最快的地區,預計複合年成長率將達到17.8%。中國自主研發的「Ascend 910C」正在填補美國制裁造成的空白,確保阿里巴巴、騰訊和百度在部署大規模語言模式方面不會落後。日本已建立2兆日圓(約134億美元)的補貼框架,以支持國內產業叢集的發展;韓國則利用其在人腦模型(HBM)領域的領先地位,推動從記憶體到加速器的垂直整合。印度的三大城市——班加羅爾、海得拉巴和孟買——已成為國家級人工智慧計畫的中心;而隨著新加坡部分解除資料中心建設凍結,東南亞各國首都也開始部署新的邊緣運算技術。
歐洲的前景取決於嚴格的能源指令,這些指令將新建設的PUE值限制在1.3以內。德國和北歐國家正在維修現有設施,採用浸沒式冷卻和後門冷卻技術,以適應高密度機架。英國人工智慧安全實驗室已採購5000個GPU用於審計最先進的模型,而法國的Mistral AI正在巴黎建造其Blackwell園區。西班牙南部和義大利因其豐富的可再生能源資源而吸引營運商,但部署計劃仍取決於電網升級方案。其他地區,特別是南美、中東和非洲,目前市場佔有率不到全球的十分之一,但沙烏地阿拉伯耗資200億美元的「NEOM」計畫和南非的約翰尼斯堡邊緣資料中心表明,這些地區將成為高成長需求的中心,進一步擴大其在全球超大規模資料中心GPU市場的佔有率。
其他好處:
- Excel格式的市場預測(ME)表
- 3個月的分析師支持
目錄
第1章:引言
- 研究假設和市場定義
- 調查範圍
第2章:調查方法
第3章執行摘要
第4章 市場狀況
- 市場概覽
- 市場促進因素
- 雲端資料中心人工智慧和機器學習工作負載激增
- 生成式人工智慧模型訓練叢集的快速擴張
- 向異構運算架構過渡
- 對雲端遊戲和3D圖形工作負載的需求不斷成長
- 基於晶片組的分散式GPU設計的興起
- 在高密度GPU機架中採用液冷技術
- 市場限制因素
- 對超大規模GPU叢集的高額資本投入
- 先進包裝和人類腦膜製造(HBM)供應鏈中的瓶頸
- 資料中心能源使用面臨越來越大的監管壓力
- 地緣政治出口限制了GPU的供應
- 產業價值鏈分析
- 監理情勢
- 技術展望
- 宏觀經濟因素對市場的影響
- 波特五力分析
第5章 市場規模與成長預測
- 依部署類型
- 雲端資料中心
- 企業/私人資料中心
- 邊緣資料中心
- 按GPU類型
- 訓練 GPU
- 用於推理的GPU
- 透過連接方式
- 基於 PCIe 的 GPU
- 高頻寬互連GPU
- 依工作負載類型
- 人工智慧(AI)和機器學習(ML)
- 高效能運算(HPC)
- 資料分析
- 圖形和視覺化
- 按地區
- 北美洲
- 美國
- 加拿大
- 墨西哥
- 歐洲
- 德國
- 英國
- 法國
- 義大利
- 其他歐洲國家
- 亞太地區
- 中國
- 日本
- 韓國
- 印度
- 東南亞
- 其他亞太國家
- 南美洲
- 中東和非洲
- 北美洲
第6章 競爭情勢
- 市場集中度
- 策略趨勢
- 市佔率分析
- 公司簡介
- NVIDIA Corporation
- Advanced Micro Devices, Inc.
- Intel Corporation
- Amazon Web Services, Inc.
- Microsoft Corporation
- Google LLC
- Alibaba Group Holding Limited(Alibaba Cloud)
- Tencent Holdings Ltd.(Tencent Cloud)
- Baidu, Inc.
- Oracle Corporation
- Huawei Technologies Co., Ltd.
- Graphcore Ltd.
- Super Micro Computer, Inc.
- Dell Technologies Inc.
- Hewlett Packard Enterprise Company
- Lenovo Group Limited
- Inspur Information Technology Co., Ltd.
- Gigabyte Technology Co., Ltd.
- ASUStek Computer Inc.
- Penguin Computing, Inc.
第7章 市場機會與未來展望
According to Mordor Intelligence, the hyperscale data center GPU market size is projected to expand from USD 31.86 billion in 2025 and USD 39.54 billion in 2026 to USD 81.95 billion by 2031, registering a 15.69% CAGR between 2026 and 2031.
This report is Segmented by Deployment Type (Cloud Data Centers, Enterprise/Private Data Centers, Edge Data Centers), GPU Type (Training GPUs, Inference GPUs), Interconnect (PCIe-Based GPUs, High-Bandwidth Interconnect GPUs), Workload Type (AI and ML, HPC, Data Analytics, and More), and Geography. The Market Forecasts are Provided in Terms of Value (USD).
Global Hyperscale Data Center Graphics Processing Unit (GPU) Market Trends and Insights
Proliferation Of AI And ML Workloads In Cloud Data Centers
Cloud platforms have converted GPUs from specialist accelerators into baseline infrastructure. New AI-optimized virtual machines on Microsoft Azure and Trainium2 instances on AWS lowered entry barriers for enterprise customers migrating legacy machine-learning pipelines. Capital allocations reflect permanence rather than experimentation; Meta reserved USD 65 billion for AI compute in 2026, chiefly for multimodal training clusters. Power density has surged 10-20-fold versus traditional servers, forcing data-center redesigns that integrate rack-level liquid cooling and revised power distribution. Workload diversity now spans vision, recommendation, and autonomy, each demanding a mix of inference-optimized cards and training-grade units, ensuring the Hyperscale data center GPU market remains on a structurally rising curve.
Rapid Scaling of Generative AI Model Training Clusters
Parameter growth from billions to trillions is compelling operators to assemble petaflop-scale clusters. xAI's Memphis complex is scaling toward 1 million GPUs by 2027, and Mistral AI's Paris facility replicates this model in Europe. Centralization maximizes equipment utilization and amortizes capex across successive model iterations, but only hyperscalers can fund the USD-billion class builds. Technically, liquid cooling and fabrics such as NVLink 5.0 cut inter-GPU latency below one microsecond, allowing 70-plus-GPU trays to appear as a single logical device. The result is a multiplier effect on the Hyperscale data center GPU market, with every uplift in model size translating to a disproportionate lift in cluster capacity.
High Capital Expenditure for Hyperscale GPU Clusters
A single rack of Blackwell GB200 NVL72 lists between USD 3 million and USD 4 million before facility costs. Oracle's USD 6.5 billion rollout underlines the minimum price of admission, while recurring power bills can hit USD 10 million per year for a 10 MW cluster. Utilization averaging 60%-70% obliges providers to overbuild capacity, extending payback periods, and squeezing mid-tier clouds. Consequently, only the largest operators with access to low-cost renewable energy can compete at the training frontier, tempering near-term growth for the Hyperscale data center GPU market.
Other drivers and restraints analyzed in the detailed report include:
- Transition Toward Heterogeneous Computing Architectures
- Growing Demand for Cloud Gaming And 3-D Graphics Workloads
- Supply Chain Bottlenecks in Advanced Packaging and HBM
For complete list of drivers and restraints, kindly check the Table Of Contents.
Segment Analysis
Edge facilities captured a 19.3% CAGR outlook versus mid-teens growth for centralized hyperscale hubs, reflecting the widening role of real-time inference in vehicles, smart-city sensors, and industrial robotics. The Hyperscale data center GPU market size linked to cloud sites remains dominant, yet its share inches lower as operators like AWS Outposts deliver cloud management on-premises. In practice, a dual-architecture equilibrium is emerging where 100-MW mega-facilities train trillion-parameter models while 1-MW micro-pods push decisions to within 10 ms of users.
Capital allocation favors both ends of the spectrum. Amazon's USD 200 billion through 2030 addresses mega-sites, whereas NVIDIA's IGX Orin shipments illustrate strong OEM appetite for edge appliances. Financial services and healthcare firms keep modest private clusters to satisfy data-sovereignty rules, a niche that still feeds the wider Hyperscale data center GPU market. As utilization analytics improve, some inference loads are expected to bounce between edge and core depending on regional demand curves.
Training-grade boards accounted for 56.7% of revenue in 2025, anchoring the cash flow engine for vendors. Yet inference-centric devices with lower precision and power budgets are growing rapidly, aided by hyperscaler in-house silicon. Inference GPUs should grow 18.5% annually, mirroring the doubling cadence of model sizes that force disaggregation across thousands of cards.
The Hyperscale data center GPU market size for inference hardware remains smaller but could exceed 40% of the total value by 2031 if conversational AI, retrieval-augmented generation, and real-time co-pilots permeate mainstream software. NVIDIA's L4, AWS Inferentia2, and Google TPU v5e exemplify the economics: fewer flops per watt but superior cost per request. Training clusters, then, reprioritize cutting-edge memory bandwidth, securing a two-tier product mix in which last-year silicon enjoys a lucrative afterlife as an inference workhorse.
Geography Analysis
North America retained a 42.8% revenue share in 2025 and continues to wield unparalleled purchase power as Amazon, Microsoft, Google, and Meta funnel USD-hundreds-of-billions into AI capacity. Export controls that restrict top-tier GPU shipments to China inadvertently redirect a larger slice of the limited supply toward domestic sites, bolstering the region's command of the Hyperscale data center GPU market. Canadian clusters in Toronto and Montreal enjoy low-cost hydroelectricity and university-sourced talent, while Mexico's budding near-shoring economy is catalyzing edge nodes tailored to logistics robotics.
Asia-Pacific is the fastest riser at a forecast 17.8% CAGR. China's home-grown Ascend 910C fills the void left by U.S. sanctions, allowing Alibaba, Tencent, and Baidu to keep pace in large language model rollouts. Japan's JPY 2 trillion subsidy pool (USD 13.4 billion) underwrites domestic clusters, and South Korea leverages HBM leadership for vertical integration spanning memory through accelerator. India's metro triad, Bangalore, Hyderabad, Mumbai, anchors sovereign AI ambitions, while Southeast Asian capitals harvest fresh edge deployments after Singapore partially lifted its data-center freeze.
Europe's prospects hinge on stringent energy directives that cap PUE at 1.3 for new builds. Germany and the Nordics retrofit facilities with immersion and rear-door cooling to host high-density racks. The United Kingdom's AI Safety Institute buys 5,000 GPUs to audit frontier models, while France's Mistral AI plants a Blackwell campus inside Paris's city limits. Renewable abundance lures operators to southern Spain and Italy, although deployment timelines remain tied to grid-upgrade schedules. Other regions, South America and the Middle East and Africa, collectively account for less than one-tenth of current value, yet Saudi Arabia's USD 20 billion NEOM blueprint and South Africa's Johannesburg edge pods foreshadow pockets of high-growth demand that will enrich the global Hyperscale data center GPU market footprint.
- NVIDIA Corporation
- Advanced Micro Devices, Inc.
- Intel Corporation
- Amazon Web Services, Inc.
- Microsoft Corporation
- Google LLC
- Alibaba Group Holding Limited (Alibaba Cloud)
- Tencent Holdings Ltd. (Tencent Cloud)
- Baidu, Inc.
- Oracle Corporation
- Huawei Technologies Co., Ltd.
- Graphcore Ltd.
- Super Micro Computer, Inc.
- Dell Technologies Inc.
- Hewlett Packard Enterprise Company
- Lenovo Group Limited
- Inspur Information Technology Co., Ltd.
- Gigabyte Technology Co., Ltd.
- ASUStek Computer Inc.
- Penguin Computing, Inc.
Additional Benefits:
- The market estimate (ME) sheet in Excel format
- 3 months of analyst support
TABLE OF CONTENTS
1 INTRODUCTION
- 1.1 Study Assumptions and Market Definition
- 1.2 Scope of the Study
2 RESEARCH METHODOLOGY
3 EXECUTIVE SUMMARY
4 MARKET LANDSCAPE
- 4.1 Market Overview
- 4.2 Market Drivers
- 4.2.1 Proliferation of AI and ML Workloads in Cloud Data Centers
- 4.2.2 Rapid Scaling of Generative AI Model Training Clusters
- 4.2.3 Transition Toward Heterogeneous Computing Architectures
- 4.2.4 Growing Demand for Cloud Gaming and 3-D Graphics Workloads
- 4.2.5 Emergence of Chiplet-Based Disaggregated GPU Designs
- 4.2.6 Adoption of Liquid Cooling for High-Density GPU Racks
- 4.3 Market Restraints
- 4.3.1 High Capital Expenditure for Hyperscale GPU Clusters
- 4.3.2 Supply Chain Bottlenecks in Advanced Packaging and HBM
- 4.3.3 Rising Regulatory Pressure on Data-Center Energy Use
- 4.3.4 Geopolitical Export Controls Limiting GPU Availability
- 4.4 Industry Value Chain Analysis
- 4.5 Regulatory Landscape
- 4.6 Technological Outlook
- 4.7 Impact of Macroeconomic Factors on the Market
- 4.8 Porter's Five Forces Analysis
- 4.8.1 Bargaining Power of Buyers
- 4.8.2 Bargaining Power of Suppliers
- 4.8.3 Threat of New Entrants
- 4.8.4 Threat of Substitutes
- 4.8.5 Competitive Rivalry
5 MARKET SIZE AND GROWTH FORECASTS (VALUE)
- 5.1 By Deployment Type
- 5.1.1 Cloud Data Centers
- 5.1.2 Enterprise / Private Data Centers
- 5.1.3 Edge Data Centers
- 5.2 By GPU Type
- 5.2.1 Training GPUs
- 5.2.2 Inference GPUs
- 5.3 By Interconnect
- 5.3.1 PCIe-Based GPUs
- 5.3.2 High-Bandwidth Interconnect GPUs
- 5.4 By Workload Type
- 5.4.1 Artificial Intelligence (AI) and Machine Learning (ML)
- 5.4.2 High-Performance Computing (HPC)
- 5.4.3 Data Analytics
- 5.4.4 Graphics and Visualization
- 5.5 By Geography
- 5.5.1 North America
- 5.5.1.1 United States
- 5.5.1.2 Canada
- 5.5.1.3 Mexico
- 5.5.2 Europe
- 5.5.2.1 Germany
- 5.5.2.2 United Kingdom
- 5.5.2.3 France
- 5.5.2.4 Italy
- 5.5.2.5 Rest of Europe
- 5.5.3 Asia-Pacific
- 5.5.3.1 China
- 5.5.3.2 Japan
- 5.5.3.3 South Korea
- 5.5.3.4 India
- 5.5.3.5 Southeast Asia
- 5.5.3.6 Rest of Asia-Pacific
- 5.5.4 South America
- 5.5.5 Middle East and Africa
- 5.5.1 North America
6 COMPETITIVE LANDSCAPE
- 6.1 Market Concentration
- 6.2 Strategic Moves
- 6.3 Market Share Analysis
- 6.4 Company Profiles (includes Global Level Overview, Market Level Overview, Core Segments, Financials as available, Strategic Information, Market Rank/Share, Products and Services, Recent Developments)
- 6.4.1 NVIDIA Corporation
- 6.4.2 Advanced Micro Devices, Inc.
- 6.4.3 Intel Corporation
- 6.4.4 Amazon Web Services, Inc.
- 6.4.5 Microsoft Corporation
- 6.4.6 Google LLC
- 6.4.7 Alibaba Group Holding Limited (Alibaba Cloud)
- 6.4.8 Tencent Holdings Ltd. (Tencent Cloud)
- 6.4.9 Baidu, Inc.
- 6.4.10 Oracle Corporation
- 6.4.11 Huawei Technologies Co., Ltd.
- 6.4.12 Graphcore Ltd.
- 6.4.13 Super Micro Computer, Inc.
- 6.4.14 Dell Technologies Inc.
- 6.4.15 Hewlett Packard Enterprise Company
- 6.4.16 Lenovo Group Limited
- 6.4.17 Inspur Information Technology Co., Ltd.
- 6.4.18 Gigabyte Technology Co., Ltd.
- 6.4.19 ASUStek Computer Inc.
- 6.4.20 Penguin Computing, Inc.
7 MARKET OPPORTUNITIES AND FUTURE OUTLOOK
- 7.1 White-Space and Unmet-Need Assessment
 圖形處理器 (GPU) 市場預測至 2034 年——按 GPU 類型、部署模式、記憶體類型、裝置類型、功能、應用程式、最終用戶和地區分類的全球分析
圖形處理器 (GPU) 市場預測至 2034 年——按 GPU 類型、部署模式、記憶體類型、裝置類型、功能、應用程式、最終用戶和地區分類的全球分析 東南亞GPU市場:市場佔有率分析、產業趨勢與統計及成長預測(2026-2031年)亞太地區整合GPU:市場佔有率分析、產業趨勢與統計及成長預測(2026-2031年)歐洲整合顯示卡市場:市場佔有率分析、產業趨勢與統計及成長預測(2026-2031 年)北美整合顯示卡:市場佔有率分析、產業趨勢與統計及成長預測(2026-2031 年)行動GPU:市場佔有率分析、產業趨勢與統計及成長預測(2026-2031年)印度GPU市場:市場佔有率分析、產業趨勢與統計及成長預測(2026-2031年)德國GPU市場:市場佔有率分析、產業趨勢與統計及成長預測(2026-2031年)日本GPU市場:市佔率分析、產業趨勢與統計及成長預測(2026-2031年)美國GPU市場:市佔率分析、產業趨勢與統計及成長預測(2026-2031年)
東南亞GPU市場:市場佔有率分析、產業趨勢與統計及成長預測(2026-2031年)亞太地區整合GPU:市場佔有率分析、產業趨勢與統計及成長預測(2026-2031年)歐洲整合顯示卡市場:市場佔有率分析、產業趨勢與統計及成長預測(2026-2031 年)北美整合顯示卡:市場佔有率分析、產業趨勢與統計及成長預測(2026-2031 年)行動GPU:市場佔有率分析、產業趨勢與統計及成長預測(2026-2031年)印度GPU市場:市場佔有率分析、產業趨勢與統計及成長預測(2026-2031年)德國GPU市場:市場佔有率分析、產業趨勢與統計及成長預測(2026-2031年)日本GPU市場:市佔率分析、產業趨勢與統計及成長預測(2026-2031年)美國GPU市場:市佔率分析、產業趨勢與統計及成長預測(2026-2031年)