


 |
市場調查報告書
商品編碼
1842511
資料分類:市場佔有率分析、產業趨勢、統計資料、成長預測(2025-2030)Data Classification - Market Share Analysis, Industry Trends & Statistics, Growth Forecasts (2025 - 2030) |
||||||
※ 本網頁內容可能與最新版本有所差異。詳細情況請與我們聯繫。
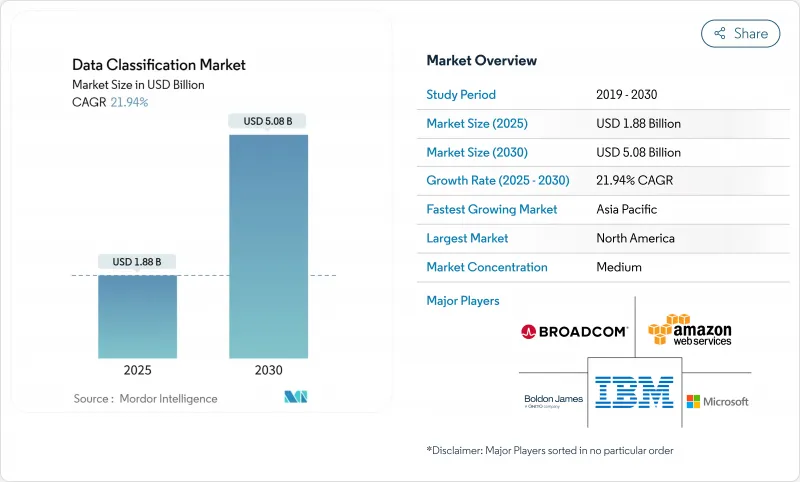
數據分類市場預計在 2025 年創造 18.8 億美元的收入,到 2030 年將達到 50.8 億美元,複合年成長率為 21.9%。
資料快速成長(估計每天產生 3.2877 億 TB)以及全球隱私法規的加強,正在推動企業採用即時、人工智慧驅動的資料標記技術,該技術可在混合雲中擴展。嵌入雲端原生架構的人工智慧分類引擎正在非結構化儲存庫中發現敏感訊息,而亞太地區的主權雲端計畫正在推動需求。到 2024 年,能源產業資料外洩的平均成本將達到 478 萬美元,這一威脅日益嚴重,進一步凸顯了自動化管治的迫切性。 AWS 和微軟等超大規模企業對區域資料中心的投資正透過降低延遲和滿足居住法規而獲得發展勢頭。
全球數據分類市場趨勢與洞察
擴大全球隱私義務
歐洲 DORA 法規和更新的 HIPAA 標準正在將合規性從定期審核轉變為持續檢驗,要求公司將分類邏輯直接建置到資料處理工作流程中。在多個司法管轄區營運的跨國公司通常以最嚴格的全球要求為基準,從而加速統一分類架構的採用。金融機構必須在幾分鐘內完成洗錢防制報告,這增加了對政策主導發現的需求。與 GDPR 相符的拉丁美洲資料主權法也施加了類似的壓力。這些要求正在縮短採購週期,推動中型市場公司轉向基於 SaaS 的工具來自動更新政策。
非結構化資料的爆炸性成長與外洩風險
非結構化儲存庫每年成長62%,導致安全團隊無法確定敏感記錄的持有者。企業報告稱,82%的文件共用權限過高,導致寶貴的設計和客戶資料外洩。能源和公用事業公司目前每周遭受1100次網路攻擊,漏洞調查發現,文件分類錯誤是根本原因。律師事務所也同樣受到共用磁碟機上未標記的客戶文件的影響。靜態規則集無法跟上動態協作平台的步伐,因此基於人工智慧的模式識別日益成為首選解決方案。
缺乏跨行業分類標準
金融監管機構對風險資料的分類與醫療保健機構不同,要求供應商維護特定產業的規則庫。跨國公司在傳輸文件時必須將GDPR術語與中國對「敏感資料」的定義相協調。這種分散化增加了客製化編碼的工作量,引發了對供應商鎖定的擔憂,並減緩了採購決策。產業聯盟正在起草開放架構提案,但採用情況仍參差不齊。因此,整合商從映射研討會而非純粹的軟體授權中獲得了大量收益。
細分分析
軟體將繼續創造最高收益,到 2024 年將佔資料分類市場的 68.5%。許可證銷售主要集中在策略引擎、發現爬蟲類和 SaaS 儀表板上。儘管如此,隨著企業尋求指導以清除長期存在的分類債務,專業服務和託管服務正以 23.9% 的複合年成長率擴張。合約通常從多Petabyte掃描開始,造成補救積壓並使內部資源緊張。託管服務提供者透過提供基於訂閱的模型再培訓、監管更新和工單分類來填補技能差距。這些合約可以跨越多年,將支出從一次性資本支出轉變為經常性營運支出。這種方法與尋求可預測預算和可審核證據的董事會產生了共鳴。服務可能佔數據分類市場的 21.5 億美元,反映了它們的戰略重要性。因此,軟體供應商將諮詢功能捆綁到高階層以確保淨利率。
第二代實施依賴持續調優,而非年度健康檢查。服務合作夥伴建立 DevSecOps 管線,並在新資料進入物件儲存時啟動分類。在業務部門之間制定共用分類法還可以縮短收購期間的部署時間。這一趨勢擴大了數據分類市場,使中型企業能夠租用專業知識,而不是僱用稀缺的專家。供應商市場現在提供符合 ISO 27001、HIPAA 或 PCI 模板的服務包,進一步實現了採用的民主化。隨著服務收益的成長,系統整合商正在收購精品諮詢顧問,以增強其領域知識並鞏固市場佔有率。
基於內容的檢測,利用正規表示式和指紋辨識來標記智慧財產權,將在2024年佔支出的43.2%。然而,機器主導的語意模型(從數百萬個標記文件中學習情境)的複合年成長率為22.8%。諸如變壓器網路之類的模式盲功能可以分析句子結構,從而提高召回率並減少誤報。 Microsoft Purview基於全球遠端檢測進行學習,並定期更新其模型,無需客戶操作。 Digital Guardian將位置和裝置姿態等上下文訊號疊加在內容線索之上,以實現風險加權標記。結合這些方法,管理員可以在不中斷業務的情況下逐步引入新引擎。
機器學習的早期採用者報告稱,由於需要人工判斷的項目減少,審核人員的工作效率提高了35%。擁有多語言檔案的組織看到了顯著的效益,因為語義模型比手動關鍵字清單更能處理語言差異。供應商正在開放API,用於整合客戶特定的本體,從而無需進行新的開發即可實現客製化的準確性。這種轉變正在推動資料分類市場的發展,將曾經的精英能力轉變為SaaS的可選項。即便如此,訓練資料仍然是利基領域的瓶頸,一些公司正在根據互惠協議共用匿名語料庫。未來預測表明,機器學習的採用將使價值實現時間從幾個季度縮短至幾週,使機器學習成為預設方法。
區域分析
北美維持領先地位,佔2024年總收入的41.0%。嚴格的監管和早期人工智慧的採用促使企業對其發現項目進行現代化改造。 BigID在2025年完成的6,000萬美元資金籌措表明,新創公司對在SEC新資訊揭露規則訂定前實現資料衛生自動化的解決方案充滿熱情。金融機構實施標籤以支援日內報告,醫療保健提供者將標籤整合到電子健康記錄中,以符合不斷發展的《健康保險流通與責任法案》(HIPAA) 擴展規定。加拿大各省的隱私權法與聯邦要求相呼應,這進一步增強了市場對此類方案的持續需求。墨西哥的高科技產業叢集正在採用雲端託管平台以滿足USMCA的資料傳輸規定,但目前這類方案的採用主要集中在跨國子公司。
亞太地區成長最快,複合年成長率達22.5%,這反映了主權雲的授權以及超超大規模資料中心業者在基礎設施方面的巨額支出。 AWS已向馬來西亞投資60億美元,NTT則向曼谷資料中心投資9,000萬美元,用於建置本地運算,以降低策略引擎的延遲。中國提案放寬對出站資料的核准,但仍將許多資料集歸類為「關鍵」資料集,並實施雙重控制。日本和韓國正在引入5G製造分類,以保護商業機密。印度IT服務出口商要求使用多租戶標記來隔離客戶數據,從而擴大可尋址的雲端用戶池。
歐洲在以金額為準方面排名第二,這得益於《數位營運彈性法案》,該法案要求到 2025 年必須進行持續控制測試。德國工業 4.0 工廠正在標記營運數據,以保護智慧財產權並遵守供應鏈安全審核。英國在脫歐後的正當性與國內創新規則之間取得平衡,而企業則在雙重政策下監控跨境流動。法國推廣主權雲區來託管公共部門工作負載,義大利則加強關鍵基礎設施保護。北歐國家是 GDPR 的早期採用者,正在試行機密運算晶片,這種晶片可以在不暴露明文的情況下進行內聯標記,為下一波創新浪潮做好準備。
其他福利:
- Excel 格式的市場預測 (ME) 表
- 3個月的分析師支持
目錄
第1章 引言
- 研究假設和市場定義
- 調查範圍
第2章調查方法
第3章執行摘要
第4章 市場狀況
- 市場概況
- 市場促進因素
- 擴大全球隱私保護範圍
- 非結構化資料爆炸性成長,資料外洩風險
- 雲端原生資料分類的需求
- 基於AI/ML的自動分類進入大規模生產
- 機密運算晶片組支援內嵌標記
- GenAI 安全需要細粒度的資料標記
- 市場限制
- 缺乏跨行業分類標準
- 與遺留資產的整合成本高
- 由於合成資料的盛行而導致的資料分類錯誤
- 同態加密減慢明文檢查速度
- 價值鏈分析
- 監管狀況
- 技術展望
- 波特五力分析
- 供應商的議價能力
- 消費者議價能力
- 新進入者的威脅
- 替代品的威脅
- 競爭對手之間的競爭強度
- 評估宏觀經濟趨勢對市場的影響
第5章市場規模及成長預測
- 按組件
- 軟體
- 服務
- 按分類方法
- 基於內容
- 基於上下文
- 基於使用者/角色
- 機器學習驅動和語義
- 按組織規模
- 主要企業
- 中小企業
- 按用途
- 存取控制和 IAM
- 管治與合規
- 電子郵件和行動保護
- 按行業
- BFSI
- 醫療保健和生命科學
- 政府和國防
- IT和電信
- 能源與公共產業
- 其他行業
- 按地區
- 北美洲
- 美國
- 加拿大
- 墨西哥
- 歐洲
- 德國
- 英國
- 法國
- 義大利
- 西班牙
- 其他歐洲國家
- 亞太地區
- 中國
- 日本
- 印度
- 韓國
- 澳洲
- 其他亞太地區
- 南美洲
- 巴西
- 阿根廷
- 其他南美
- 中東和非洲
- 中東
- 沙烏地阿拉伯
- 阿拉伯聯合大公國
- 土耳其
- 其他中東地區
- 非洲
- 南非
- 埃及
- 奈及利亞
- 其他非洲國家
- 北美洲
第6章 競爭態勢
- 市場集中度
- 策略舉措
- 市佔率分析
- 公司簡介
- Amazon Web Services
- Microsoft Corporation
- IBM Corporation
- Broadcom(Symantec)
- Google LLC
- OpenText(TITUS)
- Thales Group
- Fortra(Boldon James)
- SECLORE
- Digital Guardian
- Forcepoint
- Varonis Systems
- BigID Inc.
- Concentric AI
- Netwrix Corporation
- Spirion LLC
- Immuta Inc.
- OneTrust LLC
- PKWARE Inc.
- Palo Alto Networks
第7章 市場機會與未來展望
The data classification market size is currently generating USD 1.88 billion in 2025 and is forecast to reach USD 5.08 billion by 2030, translating into a 21.9% CAGR.
Rapid data growth, estimated at 328.77 million TB created every day, and tougher global privacy mandates are pushing enterprises to adopt real-time, AI-enabled data labeling that scales across hybrid cloud estates. AI-powered classification engines embedded in cloud-native architectures now detect sensitive information across unstructured repositories, while sovereign-cloud initiatives in Asia-Pacific propel regional demand. The rising threat landscape, where the average energy-sector breach cost hit USD 4.78 million in 2024, further underscores the urgency of automated governance. Investments by hyperscalers such as AWS and Microsoft in regional data centers add momentum by lowering latency and meeting residency rules.
Global Data Classification Market Trends and Insights
Expanding Global Privacy Mandates
European DORA rules and updated HIPAA standards shift compliance from scheduled audits to continuous verification, obliging firms to embed classification logic directly into data processing workflows. Multinational enterprises operating in multiple jurisdictions often apply the strictest global requirement as the baseline, which accelerates deployment of unified classification architectures. Financial institutions must meet anti-money-laundering reporting within minutes, increasing demand for policy-driven discovery. Similar pressure comes from Latin American data sovereignty statutes that align with GDPR. Together these mandates shorten procurement cycles, nudging even mid-sized firms toward SaaS-based tools that update policies automatically.
Explosive Growth of Unstructured Data and Breach Risk
Unstructured repositories grow 62% each year, leaving security teams blind to who holds sensitive records. Enterprises report excessive permissions on 82% of file shares, which exposes valuable designs and customer data. Energy utilities now see 1,100 weekly cyberattacks, and breach investigations show mis-classified documents as a root cause. Law practices suffer similar exposure because client files sit in shared drives without labels. AI-driven pattern recognition is increasingly chosen because static rule sets cannot keep pace with dynamic collaboration platforms.
Lack of Cross-Industry Taxonomy Standards
Financial regulators classify risk data differently from medical authorities, forcing vendors to maintain sector-specific rule libraries. Multinationals must reconcile GDPR terminology with China's definition of "important data" when transferring files. This fragmentation drives custom coding effort, increases vendor lock-in fears, and slows purchasing decisions. Industry alliances are drafting open schema proposals but adoption remains uneven. As a result, integrators earn sizeable revenue from mapping workshops rather than from pure software licenses.
Other drivers and restraints analyzed in the detailed report include:
- Cloud-Native Data Classification Demand
- AI/ML-Powered Auto-Classification Hitting Production at Scale
- High Integration Cost in Legacy Estates
For complete list of drivers and restraints, kindly check the Table Of Contents.
Segment Analysis
Software continued to generate the highest revenue, translating into 68.5% of the data classification market in 2024. License sales centered on policy engines, discovery crawlers, and SaaS dashboards. Even so, professional and managed services are scaling at a 23.9% CAGR because enterprises need guidance to clear long-standing classification debt. Engagements often begin with multi-petabyte scans that feed remediation backlogs and stretch internal resources. Managed service providers supplement skill shortages by handling model retraining, regulatory updates, and ticket triage on a subscription basis. These contracts can span several years, which shifts spending from one-time capital expense to recurring OPEX. The approach resonates with boards seeking predictable budgets and audit-ready evidence. In monetary terms, services could represent USD 2.15 billion of the data classification market size by 2030, reflecting their strategic importance. Software vendors are therefore bundling advisory capacity into premium tiers to protect margins.
Second-generation implementations rely on continuous tuning rather than annual health checks. Service partners build DevSecOps pipelines that trigger classification whenever new data lands in object storage. They also codify shared taxonomies across business units, which compresses onboarding timelines for acquisitions. The trend broadens the data classification market because mid-tier firms can rent expertise instead of hiring scarce specialists. Vendor marketplaces now list curated service bundles that align to ISO 27001, HIPAA, or PCI templates, further democratizing adoption. As services revenue accelerates, system integrators are acquiring boutique consultancies to strengthen domain knowledge and secure wallet share.
Content-based inspection held 43.2% of spending in 2024 by leveraging regex and fingerprinting to flag intellectual property. Yet ML-driven and semantic models are compounding at a 22.8% CAGR by learning context from millions of labeled documents. Pattern-blind capabilities, such as transformer networks that analyze sentence structure, lift recall rates and cut false alerts. Microsoft Purview trains on global telemetry, which fuels regular model refreshes without customer action. Digital Guardian layers contextual signals like location and device posture on top of content clues, enabling risk-weighted tagging. Combined approaches now ship as pre-configured bundles so administrators can phase in new engines without business disruption.
Early adopters report that ML lifts reviewer productivity by 35%, as fewer items require human adjudication. Organizations with multilingual archives gain measurable benefit because semantic models handle language variance better than manual keyword lists. Vendors are opening APIs to integrate customer-specific ontologies, bringing bespoke accuracy without ground-up development. The shift boosts the data classification market because it turns what was once an elite capability into a SaaS checkbox. Training data nevertheless remains a bottleneck for niche domains, prompting some firms to share anonymized corpora under mutual-benefit agreements. Over the forecast horizon, ML adoption is expected to reduce time-to-value from quarters to weeks, cementing its role as the default methodology.
The Data Classification Market Report is Segmented by Component (Software and Services), Classification Method (Content-Based, Context-Based, and More), Organization Size (Large Enterprises and Small and Medium Enterprises (SMEs)), Application (Access Control and IAM, Governance and Compliance, and More), Industry Vertical (BFSI, and More), and Geography. The Market Forecasts are Provided in Terms of Value (USD).
Geography Analysis
North America retained leadership with 41.0% of 2024 revenue because stringent regulations and early AI adoption pushed enterprises to modernize discovery programs. BigID's USD 60 million funding round in 2025 exemplifies venture appetite for solutions that automate data hygiene ahead of new SEC disclosure rules. Financial institutions deploy labeling to meet intraday reporting, while healthcare providers integrate tags into electronic medical records to comply with evolving HIPAA expansions. Canada's provincial privacy acts mirror federal requirements, reinforcing consistent demand. Mexico's tech clusters adopt cloud-hosted platforms to meet USMCA data-transfer clauses, though uptake concentrates in multinational subsidiaries.
Asia-Pacific is the fastest-growing region with a 22.5% CAGR, reflecting sovereign-cloud mandates and heavy infrastructure spending by hyperscalers. AWS pledged USD 6 billion to Malaysia and NTT committed USD 90 million to Bangkok data centers, creating local compute that reduces latency for policy engines. China proposes easing outbound data approval but still labels many datasets as "important," forcing dual controls. Japan and South Korea deploy classification in 5G manufacturing to protect trade secrets. India's IT-services exporters demand multi-tenant tagging to segregate client data, expanding the addressable pool of cloud subscribers.
Europe ranks a solid second by value, propelled by the Digital Operational Resilience Act that requires continuous control testing by 2025. Germany's Industry 4.0 plants tag operational data to safeguard intellectual property and comply with supply-chain security audits. The United Kingdom balances post-Brexit adequacy with domestic innovation rules, so firms monitor cross-border flows under dual policies. France promotes sovereign cloud zones to host public-sector workloads, while Italy tightens critical-infrastructure protections. Nordic countries, early GDPR adopters, now pilot confidential-computing chips that enable inline tagging without exposing clear text, positioning the region for next-wave innovation.
- Amazon Web Services
- Microsoft Corporation
- IBM Corporation
- Broadcom (Symantec)
- Google LLC
- OpenText (TITUS)
- Thales Group
- Fortra (Boldon James)
- SECLORE
- Digital Guardian
- Forcepoint
- Varonis Systems
- BigID Inc.
- Concentric AI
- Netwrix Corporation
- Spirion LLC
- Immuta Inc.
- OneTrust LLC
- PKWARE Inc.
- Palo Alto Networks
Additional Benefits:
- The market estimate (ME) sheet in Excel format
- 3 months of analyst support
TABLE OF CONTENTS
1 INTRODUCTION
- 1.1 Study Assumptions and Market Definition
- 1.2 Scope of the Study
2 RESEARCH METHODOLOGY
3 EXECUTIVE SUMMARY
4 MARKET LANDSCAPE
- 4.1 Market Overview
- 4.2 Market Drivers
- 4.2.1 Expanding global privacy mandates
- 4.2.2 Explosive growth of unstructured data and breach risk
- 4.2.3 Cloud-native data classification demand
- 4.2.4 AI/ML-powered auto-classification hitting production at scale
- 4.2.5 Confidential-computing chipsets enabling inline tagging
- 4.2.6 GenAI safety requiring fine-grained data labeling
- 4.3 Market Restraints
- 4.3.1 Lack of cross-industry taxonomy standards
- 4.3.2 High integration cost in legacy estates
- 4.3.3 "Classification debt" from synthetic data proliferation
- 4.3.4 Homomorphic encryption delaying clear-text inspection
- 4.4 Value Chain Analysis
- 4.5 Regulatory Landscape
- 4.6 Technological Outlook
- 4.7 Porter's Five Forces Analysis
- 4.7.1 Bargaining Power of Suppliers
- 4.7.2 Bargaining Power of Consumers
- 4.7.3 Threat of New Entrants
- 4.7.4 Threat of Substitute Products
- 4.7.5 Intensity of Competitive Rivalry
- 4.8 Assessment of the Impact of Macroeconomic Trends on the Market
5 MARKET SIZE AND GROWTH FORECASTS (VALUE)
- 5.1 By Component
- 5.1.1 Software
- 5.1.2 Services
- 5.2 By Classification Method
- 5.2.1 Content-based
- 5.2.2 Context-based
- 5.2.3 User-/Role-based
- 5.2.4 ML-driven and Semantic
- 5.3 By Organization Size
- 5.3.1 Large Enterprises
- 5.3.2 Small and Medium Enterprises (SMEs)
- 5.4 By Application
- 5.4.1 Access Control and IAM
- 5.4.2 Governance and Compliance
- 5.4.3 Email and Mobile Protection
- 5.5 By Industry Vertical
- 5.5.1 BFSI
- 5.5.2 Healthcare and Life Sciences
- 5.5.3 Government and Defence
- 5.5.4 IT and Telecom
- 5.5.5 Energy and Utilities
- 5.5.6 Other Industry Verticals
- 5.6 By Geography
- 5.6.1 North America
- 5.6.1.1 United States
- 5.6.1.2 Canada
- 5.6.1.3 Mexico
- 5.6.2 Europe
- 5.6.2.1 Germany
- 5.6.2.2 United Kingdom
- 5.6.2.3 France
- 5.6.2.4 Italy
- 5.6.2.5 Spain
- 5.6.2.6 Rest of Europe
- 5.6.3 Asia-Pacific
- 5.6.3.1 China
- 5.6.3.2 Japan
- 5.6.3.3 India
- 5.6.3.4 South Korea
- 5.6.3.5 Australia
- 5.6.3.6 Rest of Asia-Pacific
- 5.6.4 South America
- 5.6.4.1 Brazil
- 5.6.4.2 Argentina
- 5.6.4.3 Rest of South America
- 5.6.5 Middle East and Africa
- 5.6.5.1 Middle East
- 5.6.5.1.1 Saudi Arabia
- 5.6.5.1.2 United Arab Emirates
- 5.6.5.1.3 Turkey
- 5.6.5.1.4 Rest of Middle East
- 5.6.5.2 Africa
- 5.6.5.2.1 South Africa
- 5.6.5.2.2 Egypt
- 5.6.5.2.3 Nigeria
- 5.6.5.2.4 Rest of Africa
- 5.6.1 North America
6 COMPETITIVE LANDSCAPE
- 6.1 Market Concentration
- 6.2 Strategic Moves
- 6.3 Market Share Analysis
- 6.4 Company Profiles (includes Global level Overview, Market level overview, Core Segments, Financials as available, Strategic Information, Market Rank/Share for key companies, Products and Services, and Recent Developments)
- 6.4.1 Amazon Web Services
- 6.4.2 Microsoft Corporation
- 6.4.3 IBM Corporation
- 6.4.4 Broadcom (Symantec)
- 6.4.5 Google LLC
- 6.4.6 OpenText (TITUS)
- 6.4.7 Thales Group
- 6.4.8 Fortra (Boldon James)
- 6.4.9 SECLORE
- 6.4.10 Digital Guardian
- 6.4.11 Forcepoint
- 6.4.12 Varonis Systems
- 6.4.13 BigID Inc.
- 6.4.14 Concentric AI
- 6.4.15 Netwrix Corporation
- 6.4.16 Spirion LLC
- 6.4.17 Immuta Inc.
- 6.4.18 OneTrust LLC
- 6.4.19 PKWARE Inc.
- 6.4.20 Palo Alto Networks
7 MARKET OPPORTUNITIES AND FUTURE OUTLOOK
- 7.1 White-Space and Unmet-Need Assessment
 資料分類市場預測至 2032 年:按組件、資料類型、組織規模、部署類型、安全性與合規重點、最終用戶和地區分類的全球分析
資料分類市場預測至 2032 年:按組件、資料類型、組織規模、部署類型、安全性與合規重點、最終用戶和地區分類的全球分析 資料分類市場 - 全球產業規模、佔有率、趨勢、機會和預測(按組件、類型、垂直行業、地區和競爭細分,2020-2030 年)
資料分類市場 - 全球產業規模、佔有率、趨勢、機會和預測(按組件、類型、垂直行業、地區和競爭細分,2020-2030 年) 2026 年至 2032 年資料分類市場(按組件、方法、應用、最終用戶產業和地區分類)
2026 年至 2032 年資料分類市場(按組件、方法、應用、最終用戶產業和地區分類) 全球資料分類市場規模研究,按組件、分類、應用、垂直產業和區域預測 2022-2032年
全球資料分類市場規模研究,按組件、分類、應用、垂直產業和區域預測 2022-2032年 全球資料分類市場規模、佔有率和趨勢分析報告(按組成部分、按應用、按分類、按行業、按地區、展望和預測,2024-2031)
全球資料分類市場規模、佔有率和趨勢分析報告(按組成部分、按應用、按分類、按行業、按地區、展望和預測,2024-2031) 資料分類市場規模、佔有率和趨勢分析報告:2024-2030 年按組件、分類、應用、行業、地區和細分市場進行的預測
資料分類市場規模、佔有率和趨勢分析報告:2024-2030 年按組件、分類、應用、行業、地區和細分市場進行的預測