


 |
市場調查報告書
商品編碼
2064515
人工智慧訓練資料集:市場佔有率分析、產業趨勢與統計、成長預測(2026-2031)AI Training Dataset - Market Share Analysis, Industry Trends & Statistics, Growth Forecasts (2026 - 2031) |
||||||
※ 本網頁內容可能與最新版本有所差異。詳細情況請與我們聯繫。
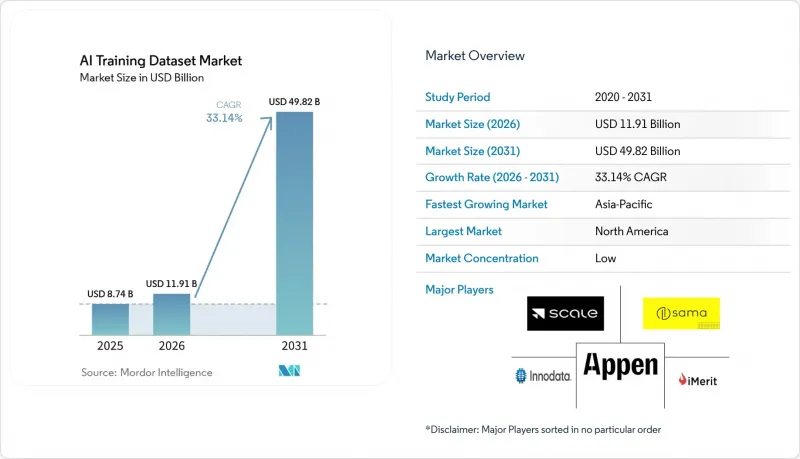
根據 Mordor Intelligence 預測,人工智慧訓練資料集市場規模將從 2025 年的 87.4 億美元成長到 2026 年的 119.1 億美元,然後在 2031 年達到 498.2 億美元,2026 年至 2031 年的複合年成長率為 33.14%。
本報告按資料模態(文字、圖像/影片、音訊/語音等)、資料集交付方式(現成資料集、自訂資料集建立等)、部署方式(本地部署等)、最終用戶產業(IT/電信、汽車/模態、醫療保健/生命科學、銀行、金融服務和保險、零售/電子商務等)以及地區進行細分。市場預測以美元計價。
全球人工智慧訓練資料集市場趨勢及洞察。
擴展多模態LLM和生成式AI工作負載
多模態大規模語言模型的激增改變了買家對人工智慧訓練資料集市場的預期。如今,供應商需要提供同步的文字-影像對、時間對齊的影片和音訊序列,以及其他能夠保持語義一致性的記錄,不僅要保證單一資料類型內的含義一致,還要保證跨模態的含義一致。這提升了能夠同時支援影像推理、影片理解和跨模態搜尋的訓練和評估的資料集的價值。這種規模挑戰體現在開放原始碼多模態資料集「MINT-1T」的發布上,該資料集整合了PDF、HTML和arXiv資料,並擴展到包含1.02兆個詞元的語料庫。類似的需求也延伸到了基於代理的系統中,這類模型不僅需要靜態標籤,還需要互動追蹤、任務演示以及來自環境的回饋。因此,人工智慧訓練資料集市場在複雜標註和跨模態品質保證領域的成長速度超過了基礎標註數量的成長速度。
受監管工作流程中對特定領域資料集的需求日益成長
由於通用語料庫不足以滿足受監管的工作流程,人工智慧訓練資料集市場正蓬勃發展。醫療保健、法律和金融等應用情境需要由合格的審核人員對資料進行匿名化、可追溯和可標註,這提升了已在受控環境下運作的供應商的價值。 PhysioNet 宣布將於 2025 年發布 ER-REASON 等資料集,進一步強化了這一趨勢,顯示機構對受控存取條件下的研究級臨床推理資料集的需求持續成長。這也是醫療保健產業在 2031 年前將成為成長最快的終端使用者領域的原因之一,因為人工智慧開發人員需要能夠支援關鍵應用的標註的臨床記錄、醫學影像和結構化記錄。此外,其成本結構也不同於一般資料操作,因為專家審核、匿名化和審計文件已整合到交付流程中,而不是後期添加。這使得融入受監管工作流程的供應商的利潤率更加穩健,從而使進入該領域的供應商在人工智慧訓練資料集市場中擁有持續優勢。
資料隱私、主權和合規性的負擔
隱私和合規法規仍然是人工智慧訓練資料集市場面臨的最大結構性限制。歐盟人工智慧法案於2026年8月2日全面生效,該法案強制要求高風險人工智慧系統使用相關、具代表性且可追溯性強、文件齊全的資料集。這些義務與GDPR的資料最小化規則相互作用,可能會限制訓練語料庫中可保留的個人資訊量。這些相互衝突的要求增加了專案成本,因為服務提供者需要本地化的工作流程、更嚴格的文件以及更多的法律審查,才能將資料部署到生產環境中。這在醫療保健、金融和公共部門的部署中尤其具有挑戰性,因為這些領域必須同時證明資料的代表性和隱私性。儘管人工智慧訓練資料集市場預計將持續成長,但無法支援資料來源、本地化和可審計性的服務提供者將面臨基本客群縮小的困境。
細分市場分析
到2025年,文字資料將佔人工智慧訓練資料集的46.53%,成為最大的模態。這一主導地位反映了前沿和企業開發專案中對預訓練語料庫、特定任務微調資料集以及大規模語言模型評估材料的持續需求。語言學習模型(LLM)的訓練結構仍然以文字為中心,因為每個階段——預訓練、監督微調和對齊——都需要不同的文字資源,而且每個步驟對品質的要求都比前一個步驟更高。這導致了對授權語料庫、專用指令集、多語言材料和人類偏好資料持續的需求。 NVIDIA於2025年發布的HelpSteer3-Preference生動地展現了這一轉變,它以CC-BY-4.0授權協議提供了超過4萬個涵蓋STEM、程式設計和多語言任務的人工標註偏好對。實際上,這意味著儘管其他模式興起,但人工智慧訓練資料集市場仍然依賴文字作為模型能力的基礎。
語音和音訊資料的需求保持穩定,因為在語音介面、多語言辨識和資源受限語言領域,標註語音和副語言特徵仍然不可或缺。隨著開發者擴大將文字、圖像、音訊和結構化上下文整合到單一訓練流程中,多模態資料的重要性日益凸顯。影片數據是成長最快的模態,預計到2031年將達到33.94%的複合年成長率。這主要得益於視訊片段級對齊、高密度字幕以及視覺語言和實體人工智慧系統的時間順序事件處理。與處理靜態影像相比,影片資料在供應方面面臨更多挑戰,因為所有資訊——動作邊界、場景切換、同步指令——都需要精確的時間控制和審核。 MINT-1T展示了訓練具有競爭力的多模態模型所需的龐大基礎設施,並將開放原始碼多模態語料庫的詞元數量推向了大規模以往資料集的水平。因此,人工智慧訓練資料集產業正在向以影片為主要驅動力、文字仍作為基礎的模型轉型。
2025年,現成資料集在人工智慧訓練資料集市場仍維持主導地位,無論採用何種交付方式,市佔率均達到46.84%。當速度、成本控制和標準用例比高度客製化更為重要時,買家更傾向於這種模式。基於目錄的採購方式對於早期模型開發、測試和通用訓練任務仍然十分有效,因為這些任務通常只需要通用基準和豐富的語料庫。隨著市場的成熟,結構化元資料和標準化授權條款的引入進一步增強了這一優勢,降低了採購摩擦。 2025年推出的人工智慧訓練內容授權框架(例如版權授權機構(CLA)的「生成式人工智慧訓練授權」)體現了朝向更正式的交易模式的轉變。這將使人工智慧訓練資料集市場能夠在企業需求日益具體化的同時,維持大規模標準化的供應管道。
創建客製化資料集是成長最快的服務,預計到2031年複合年成長率將達到33.74%。這是因為受監管的行業特定買家需要涵蓋產品語料庫,而這些產品在目錄系統中大多無法找到。醫療保健、銀行、金融和保險 (BFSI)、政府機構和其他經過嚴格審查的使用者需要客製化資料集,這些資料集必須符合既定的工作流程,並包含來源文件、合規支援和偏見審查。獲得版權許可的內容也在這一轉變中發揮了作用,例如,《紐約時報》和亞馬遜於2025年5月達成的許可協議,允許亞馬遜訪問其新聞編輯室檔案和相關資產用於人工智慧訓練。這導致人工智慧訓練資料集市場的收入結構更加兩極化,一方面是大量生產的標準產品,另一方面是小批量、高利潤的客製化服務。能夠將專家標註、法律許可和符合審計要求的文件整合到單一交付模式中的供應商將具有優勢。因此,人工智慧訓練資料集產業正從單一主導的採購方式轉向更多層次的商業結構。
區域分析
到2025年,北美將佔據人工智慧訓練資料集市場34.11%的佔有率。這主要得益於先進的人工智慧實驗室、超大規模資料中心業者以及企業買家對經過專家標註且版權已獲批准數據的優先需求。美國在醫療保健、金融服務和國防等領域的高支出用戶正在部署先進模型,從而推動了市場需求。 Scale AI在2025年至2026年間的辦公室擴張計畫凸顯了服務供應商在關鍵企業人工智慧中心附近拓展業務的趨勢。加拿大透過自動駕駛汽車開發和雙語自然語言處理(NLP)業務來支持市場需求,而墨西哥則為與美國相關的標註項目提供了具成本效益的勞動力。
預計到2031年,亞太地區將以34.14%的複合年成長率成長,成為市場中成長最快的地區。中國、印度和韓國政府主導的人工智慧計畫正在推動製造業、醫療保健、智慧城市和自動駕駛系統等領域的需求。印度不僅擁有大規模的標註人才庫,而且在醫療保健、法律和推理資料領域,專家級工作流程也不斷擴展。中國正透過公共和私人人工智慧投資擴大需求,而日本和韓國則專注於汽車、半導體和精密製造等需要感測器和多模態數據的產業的人工智慧專案。
歐洲人工智慧訓練資料集市場更多地受到合規性主導的採購而非標註量的影響。歐盟《人工智慧法》第10條要求高風險應用的開發者提供經過文件記錄、可審計且檢驗無偏見的資料集,這有利於歐洲的專業供應商。 AI Verse在2026年1月籌集的500萬歐元(530萬美元)資金反映出,在合規性要求日益提高的背景下,人們對合成電腦視覺數據的興趣日益濃厚。在以巴西為首的南美洲,對本地文本和地理空間資料的金融科技和農業技術的需求正在興起。中東和非洲地區尚處於起步階段,但卡達、沙烏地阿拉伯和阿拉伯聯合大公國在國內數據採購和非結構化數據開發方面正在取得進展。
其他好處:
- Excel格式的市場預測(ME)表
- 3個月的分析師支持
目錄
第1章:引言
- 市場分析與定義的前提條件
- 分析範圍
第2章 分析方法
第3章執行摘要
第4章 市場狀況
- 市場概覽
- 市場促進因素
- 擴展多模態LLM和生成式AI工作負載
- 受監管工作流程中對特定領域資料集的需求日益成長
- 擴大合成數據和模擬數據的使用
- 物理人工智慧和自主系統的擴展
- 訓練後偏好轉變、智慧體軌跡與評估數據
- 已獲版權授權的內容市場成長
- 市場限制因素
- 資料隱私、主權和合規性的負擔
- 專家標註和品質保證高成本。
- 人工智慧產生的網路內容對訓練資料造成污染
- 對碎片化許可的來源和儲存歷史的要求
- 宏觀經濟因素對市場的影響
- 產業價值鏈分析
- 監理情勢
- 技術展望
- 波特五力分析
第5章:預測市場規模與成長率
- 按數據模態
- 文字
- 圖片和影片
- 語音和言語
- 多模態和富含感測器的數據
- 資料集交付方式
- 預先建置資料集
- 建立自訂資料集
- 資料集市場和授權交易
- 透過部署方法
- 現場
- 雲
- 混合
- 按最終用戶行業分類
- IT/通訊
- 汽車與出行
- 醫學與生命科學
- 銀行、金融服務和保險業 (BFSI)
- 零售與電子商務
- 政府/國防
- 媒體與娛樂
- 製造業和工業
- 按地區
- 北美洲
- 美國
- 加拿大
- 墨西哥
- 南美洲
- 巴西
- 阿根廷
- 其他南美國家
- 歐洲
- 英國
- 德國
- 法國
- 義大利
- 西班牙
- 其他歐洲國家
- 亞太地區
- 中國
- 日本
- 印度
- 韓國
- 其他亞太國家
- 中東和非洲
- 中東
- 阿拉伯聯合大公國
- 沙烏地阿拉伯
- 其他中東國家
- 非洲
- 南非
- 埃及
- 其他非洲國家
- 中東
- 北美洲
第6章 競爭情勢
- 市場集中度
- 策略趨勢
- 市佔率分析
- 公司簡介
- Scale AI, Inc.
- Appen Limited
- Samasource Impact Sourcing, Inc.
- iMerit Technology Services Private Limited
- Labelbox, Inc.
- SuperAnnotate AI, Inc.
- DefinedCrowd Corporation
- Dataloop Ltd.
- Kili Technology SAS
- Toloka AI BV
- Shaip
- Cogito Tech LLC
- Clickworker GmbH
- LXT AI, Inc.
- CloudFactory Limited
- NEXDATA TECHNOLOGY INC.
- Innodata Inc.
- Snorkel AI, Inc.
- Tonic.ai
- V7 Ltd.
第7章 市場機會與未來展望
According to Mordor Intelligence, the aI training dataset market size is expected to grow from USD 8.74 billion in 2025 to USD 11.91 billion in 2026 and is forecast to reach USD 49.82 billion by 2031 at 33.14% CAGR over 2026-2031.
This report is Segmented by Data Modality (Text, Image and Video, Audio and Speech, and More), Dataset Offering (Off-The-Shelf Datasets, Custom Dataset Creation, and More), Deployment (On-Premises, and More), End-User Industry (IT and Telecom, Automotive and Modality, Healthcare and Life Sciences, BFSI, Retail and E-Commerce, and More), and Geography. The Market Forecasts are Provided in Terms of Value (USD).
Global AI Training Dataset Market Trends and Insights
Expansion of Multimodal LLMs and Generative AI Workloads
The spread of multimodal large language models has changed what buyers expect from the AI training dataset market. Providers now need to supply synchronized text-image pairs, time-aligned video-audio sequences, and other records that preserve meaning across modalities rather than within a single data type alone. This has raised the value of datasets that can support both training and evaluation for image reasoning, video understanding, and cross-modal retrieval. The scaling challenge is visible in the MINT-1T release, which expanded open-source multimodal data by combining PDFs, HTML, and arXiv material into a 1.02 trillion-token corpus. The same demand is carried into agentic systems, where models need interaction traces, task demonstrations, and environment feedback beyond static labels. As a result, the artificial intelligence training dataset market is seeing faster growth in complex annotation and cross-modal quality assurance than in basic labeling volume.
Rising Demand for Domain-Specific Datasets in Regulated Workflows
The AI training dataset market is gaining momentum as regulated workflows require general-purpose corpora that are not sufficient. Healthcare, legal, and financial use cases require data that is de-identified, traceable, and labeled by qualified reviewers, which increases the value of suppliers that already operate in controlled environments. PhysioNet expanded on that pattern in 2025 with releases such as ER-REASON, which demonstrated ongoing institutional demand for research-grade clinical reasoning datasets under governed access terms. This is one reason healthcare is the fastest-growing end-user segment through 2031, as AI developers need annotated clinical notes, medical imaging, and structured records that can support high-stakes applications. The cost profile is also different from general data work because expert review, de-identification, and audit documentation are built into delivery rather than added later. That keeps margins firmer for providers embedded in regulated workflows and makes domain access a durable advantage in the artificial intelligence training dataset market.
Data Privacy, Sovereignty, and Compliance Burdens
Privacy and compliance rules remain the most structural restraint on the AI training dataset market. The EU AI Act enters full enforcement on August 2, 2026, and requires high-risk AI systems to use datasets that are relevant, representative, and documented with strong traceability. Those obligations interact with GDPR data minimization rules, which can limit the amount of personal information that may be retained in training corpora. That tension increases project costs because providers need localized workflows, stronger documentation, and more legal review before data can move into production. It is especially difficult in healthcare, finance, and public-sector deployments, where representativeness and privacy must be demonstrated simultaneously. The AI training dataset market will continue to grow, but providers that cannot support provenance, localization, and auditability will face a narrower addressable customer base.
Other drivers and restraints analyzed in the detailed report include:
- Greater Use of Synthetic and Simulated Data
- Scaling of Physical AI and Autonomous Systems
- High Cost of Expert Annotation and Quality Assurance
For complete list of drivers and restraints, kindly check the Table Of Contents.
Segment Analysis
Text data accounted for 46.53% of the AI training dataset in 2025, making it the largest modality. That lead reflected continued demand for pretraining corpora, instruction-tuning datasets, and evaluation material for large language models across both frontier and enterprise development programs. The structure of LLM training still favors text because pretraining, supervised fine-tuning, and alignment each require distinct text assets, and each step imposes higher quality thresholds than the one before. This has kept demand steady for licensed corpora, specialist instruction sets, multilingual material, and human preference data. NVIDIA's HelpSteer3-Preference release in 2025 illustrated that shift by providing more than 40,000 human-annotated preference pairs across STEM, coding, and multilingual tasks under a CC-BY-4.0 license. In practice, this means the AI training dataset market continues to rely on text as the foundation for model capabilities, even as other modalities gain ground.
Audio and speech data remain stable because voice interfaces, multilingual recognition, and low-resource language initiatives still require labeled speech and paralinguistic features. Multimodal data is gaining importance as developers increasingly combine text with image, audio, and structured context inside a single training flow. Video data is the fastest-growing modality, with a 33.94% CAGR through 2031, driven by clip-level alignment, dense captioning, and temporally ordered events for vision-language and physical AI systems. The supply challenge is more severe in video than in static-image work because action boundaries, scene changes, and synchronized instructions all require precise timing and review. MINT-1T demonstrated the scale of infrastructure needed to train competitive multimodal models, pushing open-source multimodal corpora to far larger token volumes than earlier datasets. As a result, the AI training dataset industry is moving toward a model in which text remains foundational, while video becomes the primary driver of higher-value annotation demand.
Off-the-shelf datasets accounted for 46.84% of the AI training dataset market in 2025, maintaining their leading position across offering types. Buyers favored this model when speed, cost control, and standard use cases mattered more than deep customization. Catalog-based procurement is still useful for early model development, testing, and generalized training tasks where common benchmarks and broad corpora are acceptable. That advantage is reinforced by the maturing marketplace layer, where structured metadata and standardized license terms reduce procurement friction. The launch of licensing structures for AI training content in 2025, including the Copyright Licensing Agency's Generative AI Training License, reflected the move toward more formalized exchange models. This helps the AI training dataset market maintain a large standardized supply channel even as enterprise requirements become more specific.
Custom dataset creation is the fastest-growing offering, with a 33.74% CAGR through 2031, because regulated and domain-heavy buyers need corpora that catalog products that are rarely provided by cataloging systems. Healthcare, BFSI, government, and other high-scrutiny users want bespoke datasets with documented provenance, compliance support, and bias review that can fit a defined workflow. Rights-cleared content is part of that shift, as shown by the New York Times licensing agreement with Amazon in May 2025 for AI training access to newsroom archives and affiliated properties. This creates a more split revenue structure inside the AI training dataset market, with high-volume standard products on one side and lower-volume, higher-margin custom work on the other. It also favors providers that can combine expert annotation, legal clearance, and audit-ready documentation within a single delivery model. The AI training dataset industry is therefore moving toward a more layered commercial structure rather than a single dominant procurement format.
Geography Analysis
North America accounted for 34.11% of the AI training dataset market share in 2025, driven by frontier AI labs, hyperscaler infrastructure, and enterprise buyers prioritizing expert-annotated, rights-cleared data. The U.S. leads demand with high-spend users in healthcare, financial services, and defense, deploying advanced models. Scale AI's 2025-2026 office expansion highlighted providers growing near major enterprise AI hubs. Canada supports demand with autonomous vehicle development and bilingual NLP work, while Mexico offers cost-efficient labor for U.S.-linked annotation programs.
Asia-Pacific is projected to grow at a 34.14% CAGR, the fastest in the market, through 2031. Government-backed AI programs in China, India, and South Korea drive demand across manufacturing, healthcare, smart cities, and autonomous systems. India combines a large annotation labor pool with growing expert-level workflows in medical, legal, and reasoning data. China boosts demand through public and private AI investments, while Japan and South Korea focus on automotive, semiconductor, and precision manufacturing AI programs requiring sensors and multimodal data.
Europe's AI training dataset market is shaped by compliance-driven procurement rather than annotation volume. The EU AI Act's Article 10 pushes developers toward documented, auditable, and bias-examined datasets for high-risk applications, favoring specialist European providers. AI Verse's EUR 5 million (USD 5.3 million) January 2026 funding reflects interest in synthetic computer vision data amid compliance needs. South America, led by Brazil, sees emerging demand for fintech and agritech that requires local text and geospatial data. The Middle East and Africa are at early stages, with Qatar, Saudi Arabia, and the UAE advancing domestic data procurement and the development of unstructured data.
- Scale AI, Inc.
- Appen Limited
- Samasource Impact Sourcing, Inc.
- iMerit Technology Services Private Limited
- Labelbox, Inc.
- SuperAnnotate AI, Inc.
- DefinedCrowd Corporation
- Dataloop Ltd.
- Kili Technology SAS
- Toloka AI B.V.
- Shaip
- Cogito Tech LLC
- Clickworker GmbH
- LXT AI, Inc.
- CloudFactory Limited
- NEXDATA TECHNOLOGY INC.
- Innodata Inc.
- Snorkel AI, Inc.
- Tonic.ai
- V7 Ltd.
Additional Benefits:
- The market estimate (ME) sheet in Excel format
- 3 months of analyst support
TABLE OF CONTENTS
1 INTRODUCTION
- 1.1 Study Assumptions and Market Definition
- 1.2 Scope of the Study
2 RESEARCH METHODOLOGY
3 EXECUTIVE SUMMARY
4 MARKET LANDSCAPE
- 4.1 Market Overview
- 4.2 Market Drivers
- 4.2.1 Expansion of Multimodal LLMs and Generative AI Workloads
- 4.2.2 Rising Demand for Domain-Specific Datasets in Regulated Workflows
- 4.2.3 Greater Use of Synthetic and Simulated Data
- 4.2.4 Scaling of Physical AI and Autonomous Systems
- 4.2.5 Shift Toward Post-Training Preference, Agent Trajectory, and Evaluation Data
- 4.2.6 Growth of Rights-Cleared Licensed Content Markets
- 4.3 Market Restraints
- 4.3.1 Data Privacy, Sovereignty, and Compliance Burdens
- 4.3.2 High Cost of Expert Annotation and Quality Assurance
- 4.3.3 Training-Data Contamination from AI-Generated Web Content
- 4.3.4 Fragmented Licensing Provenance and Chain-of-Custody Requirements
- 4.4 Impact of Macroeconomic Factors on the Market
- 4.5 Industry Value Chain Analysis
- 4.6 Regulatory Landscape
- 4.7 Technological Outlook
- 4.8 Porter's Five Forces Analysis
- 4.8.1 Bargaining Power of Suppliers
- 4.8.2 Bargaining Power of Buyers
- 4.8.3 Threat of New Entrants
- 4.8.4 Threat of Substitutes
- 4.8.5 Intensity of Competitive Rivalry
5 MARKET SIZE AND GROWTH FORECASTS (VALUE)
- 5.1 By Data Modality
- 5.1.1 Text
- 5.1.2 Image and Video
- 5.1.3 Audio and Speech
- 5.1.4 Multimodal and Sensor-Rich Data
- 5.2 By Dataset Offering
- 5.2.1 Off-the-Shelf Datasets
- 5.2.2 Custom Dataset Creation
- 5.2.3 Dataset Marketplaces and Licensed Exchanges
- 5.3 By Deployment Model
- 5.3.1 On-premises
- 5.3.2 Cloud
- 5.3.3 Hybrid
- 5.4 By End-User Industry
- 5.4.1 IT and Telecom
- 5.4.2 Automotive and Mobility
- 5.4.3 Healthcare and Life Sciences
- 5.4.4 BFSI
- 5.4.5 Retail and E-commerce
- 5.4.6 Government and Defense
- 5.4.7 Media and Entertainment
- 5.4.8 Manufacturing and Industrial
- 5.5 By Geography
- 5.5.1 North America
- 5.5.1.1 United States
- 5.5.1.2 Canada
- 5.5.1.3 Mexico
- 5.5.2 South America
- 5.5.2.1 Brazil
- 5.5.2.2 Argentina
- 5.5.2.3 Rest of South America
- 5.5.3 Europe
- 5.5.3.1 United Kingdom
- 5.5.3.2 Germany
- 5.5.3.3 France
- 5.5.3.4 Italy
- 5.5.3.5 Spain
- 5.5.3.6 Rest of Europe
- 5.5.4 Asia-Pacific
- 5.5.4.1 China
- 5.5.4.2 Japan
- 5.5.4.3 India
- 5.5.4.4 South Korea
- 5.5.4.5 Rest of Asia-Pacific
- 5.5.5 Middle East and Africa
- 5.5.5.1 Middle East
- 5.5.5.1.1 United Arab Emirates
- 5.5.5.1.2 Saudi Arabia
- 5.5.5.1.3 Rest of Middle East
- 5.5.5.2 Africa
- 5.5.5.2.1 South Africa
- 5.5.5.2.2 Egypt
- 5.5.5.2.3 Rest of Africa
- 5.5.5.1 Middle East
- 5.5.1 North America
6 COMPETITIVE LANDSCAPE
- 6.1 Market Concentration
- 6.2 Strategic Moves
- 6.3 Market Share Analysis
- 6.4 Company Profiles (includes Global Level Overview, Market Level Overview, Core Segments, Financials as available, Strategic Information, Market Rank/Share, Products and Services, Recent Developments)
- 6.4.1 Scale AI, Inc.
- 6.4.2 Appen Limited
- 6.4.3 Samasource Impact Sourcing, Inc.
- 6.4.4 iMerit Technology Services Private Limited
- 6.4.5 Labelbox, Inc.
- 6.4.6 SuperAnnotate AI, Inc.
- 6.4.7 DefinedCrowd Corporation
- 6.4.8 Dataloop Ltd.
- 6.4.9 Kili Technology SAS
- 6.4.10 Toloka AI B.V.
- 6.4.11 Shaip
- 6.4.12 Cogito Tech LLC
- 6.4.13 Clickworker GmbH
- 6.4.14 LXT AI, Inc.
- 6.4.15 CloudFactory Limited
- 6.4.16 NEXDATA TECHNOLOGY INC.
- 6.4.17 Innodata Inc.
- 6.4.18 Snorkel AI, Inc.
- 6.4.19 Tonic.ai
- 6.4.20 V7 Ltd.
7 MARKET OPPORTUNITIES AND FUTURE OUTLOOK
- 7.1 White-Space and Unmet-Need Assessment
 人工智慧訓練資料市場預測至2034年-按資料類型、資料來源、標註類型、部署模式、應用、最終使用者和地區分類的全球分析資料中心人工智慧開發市場預測至2034年-按組件、資料類型、部署模式、資料生命週期階段、應用、最終使用者和地區分類的全球分析
人工智慧訓練資料市場預測至2034年-按資料類型、資料來源、標註類型、部署模式、應用、最終使用者和地區分類的全球分析資料中心人工智慧開發市場預測至2034年-按組件、資料類型、部署模式、資料生命週期階段、應用、最終使用者和地區分類的全球分析 2026-2030年全球人工智慧訓練資料集市場人工智慧模型訓練資料平台市場預測至2034年-全球分析(按組件、部署模式、資料類型、解決方案功能、組織規模、最終用戶和地區分類)
2026-2030年全球人工智慧訓練資料集市場人工智慧模型訓練資料平台市場預測至2034年-全球分析(按組件、部署模式、資料類型、解決方案功能、組織規模、最終用戶和地區分類) 2026年全球人工智慧(AI)合成數據市場報告2026年全球合成表格形式資料產生軟體市場報告2026年全球智慧訓練資訊服務市場報告
2026年全球人工智慧(AI)合成數據市場報告2026年全球合成表格形式資料產生軟體市場報告2026年全球智慧訓練資訊服務市場報告 AI訓練伺服器PCB市場報告:趨勢、預測與競爭分析(至2035年)2026年全球培訓數據平台市場報告
AI訓練伺服器PCB市場報告:趨勢、預測與競爭分析(至2035年)2026年全球培訓數據平台市場報告 人工智慧訓練資料集市場:2026-2032年全球市場預測(按資料類型、組件、標註類型、來源、技術、人工智慧類型、部署模式和應用分類)
人工智慧訓練資料集市場:2026-2032年全球市場預測(按資料類型、組件、標註類型、來源、技術、人工智慧類型、部署模式和應用分類)